
計算機網路技術與服務/遷移到 IPv6
在遷移階段,主機應該逐漸開始能夠到達 IPv6 目標,同時保持能夠到達 IPv4 目標。遷移所有網路裝置是一個必要的條件,但不是充分條件:使用者需要透過為整個網路制定新的地址計劃來使它們協同工作。
在應用程式中引入 IPv6 支援會導致需要更改原始碼
- 伺服器:伺服器上執行的程序應該開啟兩個執行緒,一個監聽 IPv4 套接字,另一個監聽 IPv6 套接字,以便能夠服務於 IPv4 和 IPv6 請求;
- 客戶端:諸如 Web 瀏覽器之類的應用程式應該能夠以新格式列印輸出並獲得輸入地址。
-
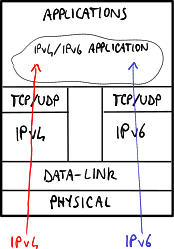 雙棧,無雙層。
雙棧,無雙層。 -
 雙棧,有雙層。
雙棧,有雙層。


應用程式主要依賴於作業系統庫,這些庫可以透過採用 **雙棧** 方法來引入 IPv6 支援
- 無雙層:作業系統獨立處理 IPv4 和 IPv6 地址→軟體應該能夠管理 IPv4 和 IPv6 地址;
- 有雙層:作業系統能夠將 IPv4 地址轉換為 IPv4 對映的 IPv6 地址→軟體可以只支援 IPv6 地址,而無需關心 IPv4 地址。
有雙層的變體是最常用的,因為它將複雜性轉移到作業系統核心。
雖然理論上交換機應該不受第 3 層更改的影響,因為它們的工作範圍僅限於第 2 層,但一些附加功能可能會出現問題:例如 **IGMP 偵聽**,用於過濾傳入多播資料包的功能,需要檢視資料包內部→由於資料包格式和欄位發生了變化,交換機無法識別多播 IPv6 資料包,因此會丟棄它們。
如今,大多數路由器都已準備好支援 IPv6,即使 IPv6 的效能仍然比 IPv4 差,因為缺乏經驗和流量需求較低。
典型情況下,支援 IPv6 的路由器採用雙棧“夜航”式方法:IPv4 和 IPv6 由傳輸層兩個獨立的棧支援→這需要所有元件的完整複製:路由協議、路由表、訪問列表等。
IPv6 中的路由與 IPv4 的執行方式相同,但它需要兩個不同的路由表,一個用於 IPv4 路由,另一個用於 IPv6 路由。IPv6 路由表可以儲存多種型別的條目,包括
- 間接條目(O/S 程式碼):它們指定要將資料包傳送到遠端鏈路的下一跳路由器的介面地址,通常是鏈路本地地址;
- 直接條目:它們指定路由器本身用於將資料包傳送到本地鏈路的介面;
- 連線的網路(C 程式碼):它們指定本地鏈路的網路字首;
- 介面地址(L 程式碼):它們指定本地鏈路中的介面識別符號。
支援 IPv6 的路由協議可以採用兩種方法
- 整合路由(例如 BGP):協議允許同時交換 IPv4 和 IPv6 路由資訊→屬於同一目的地的 IPv4 和 IPv6 地址可以透過單條訊息傳輸→效率更高;
- 夜晚的船隻 (例如 RIP、OSPF):該協議只允許交換 IPv6 路由資訊 → 給定一個目標,需要傳送一個訊息獲取其 IPv4 地址,另一個訊息獲取其 IPv6 地址,並且這些訊息完全獨立 → 更高的靈活度:可以使用兩種不同的協議,一種用於 IPv4 路由資訊,另一種用於 IPv6 路由資訊。
支援 IPv6 的 DNS 可以將兩個 IP 地址對映到同一個別名:一個 IPv4 地址和一個 IPv6 地址 → 公共目標可以透過 IPv4 或 IPv6 訪問。
支援 IPv6 的 DNS 不僅可以透過 IPv6 返回 IPv6 地址,還可以透過 IPv4 返回:實際上,DNS 訊息屬於應用程式層,因此用於轉發 DNS 查詢和應答的傳輸層無關緊要。DNSv6 查詢透過以下命令執行set q=aaaa.
一家公司可能決定也透過 IPv6 提供對其公共網站的訪問。然而,目前大多數流量是透過 IPv4 進行的,因此通常,IPv4 流量的服務在效能和容錯性方面比 IPv6 流量服務更可靠。因此,公司,尤其是如果其業務建立在網站上的話,不希望透過 IPv6 連線的使用者因效能問題而選擇其他競爭對手的網站。一種可能的解決方案是執行一些初步評估,以測試使用者和公司伺服器之間連線的效能,並在 DNS 中實現額外的機制:它們應該能夠檢視 DNS 查詢的源地址,並在沒有執行連線評估時只返回 IPv4 地址,或者在效能足夠好時返回 IPv4 和 IPv6 地址。
網路不會從第一天起就相容 IPv6 → IPv6 流量可能需要穿越僅支援 IPv4 的網路部分。面向網路的隧道解決方案即使在僅支援 IPv4 的基礎設施之間連線,也能使 IPv6 網路之間實現連線,這可以透過將 IPv6 資料包封裝在 IPv4 首部中來實現,只是為了在隧道中進行傳輸。

隧道資料包的大小,包括 20 位元組長的 IPv4 首部,不能超過 IPv4 資料包的最大大小 → 兩種解決方案是可能的
- 分片:路由器應該在將 IPv4 資料包傳送到隧道之前對其進行分片 → 由於效能原因,分片已過時;
- 更小的 IPv6 資料包:主機應該生成具有更小 MTU 大小的 IPv6 資料包,以考慮由於插入 IPv4 首部而導致的額外大小 → 路由器可以透過 '路由器通告' ICMPv6 訊息指定允許的 MTU 大小。
面向主機的隧道解決方案對於主機來說更加即插即用,但它們不是專業的解決方案,不能解決 IPv4 地址短缺的問題,因為每臺主機仍然需要一個 IPv4 地址。這類解決方案有
- 使用 IPv6 IPv4 相容地址,在主機或路由器上進行隧道終止;
- 6over4;
- ISATAP。
它們假設雙棧主機在需要聯絡 IPv4 目標時,會將 IPv6 資料包傳送到一個 IPv4 相容的 IPv6 地址,該地址的 96 位最高有效位為零,其餘 32 位與目標 IPv4 地址的 32 位一致。然後,這個 IPv6 資料包被封裝在一個 IPv4 資料包中,其目標地址取決於您是要在目標主機上終止隧道還是在雙棧路由器上終止隧道,具體來說是
- 端到端終止:雙棧主機上的偽介面將資料包封裝在一個目標為要聯絡的主機的 IPv4 資料包中;
- 路由器雙棧終止:主機上的偽介面將目標為主機的包傳送到雙棧路由器的 IPv4 地址,因此
- 會為目標生成一個 IPv6 IPv4 相容地址,如前所述;
- IPv6 資料包被封裝在一個目標為雙棧路由器的 IPv4 資料包中;
- 雙棧路由器解封裝資料包並將其傳送到目標主機。
其思路是透過 IPv4 模擬一個支援多播的本地網路。實際上,對於透過底層乙太網連線兩臺 IPv6 主機,會使用鄰居發現,並依賴於乙太網具有廣播機制這一事實,在這個解決方案中,我們假設 IPv4 是更低層的協議,並將鄰居發現更改為查詢 IPv4 地址而不是 MAC 地址。這個討論可以推廣到我們想要連線的不是單個主機,而是透過雙棧路由器在 IPv4 網路中通訊的 IPv6 網路雲的情況。在這種情況下,除了鄰居發現之外,還可以使用修改後的路由器發現,以便傳送路由器請求,以發現連線到主機 IPv4 網路的路由器的 IPv4 地址,這些路由器允許到達各種 IPv6 網路;實際上,從路由器通告中,主機可以獲取有關可以從該路由器到達的 IPv6 網路的資訊。
這個解決方案的問題是使用了 IPv4 多播,而 IPv4 多播通常在涉及不同提供商的網路中被停用。這個解決方案可以在您控制整個網路時使用:因此,它不能用於將全域性網路從 IPv4 遷移到 IPv6。
根據 RFC 的提議,IPv6 地址被對映到 IPv4 地址:實際上,IPv4 地址被用作目標 IPv6 地址的介面識別符號。這將使迄今為止說明的機制變得不必要,因為主機可以直接進行隧道傳輸,而無需鄰居發現來了解 IPv4 地址。這顯然在 IPv6 地址不是從 IPv4 地址構建的情況下不適用,因此仍然需要更通用的機制來聯絡路由器。因此,假設只知道一個 IPv6 地址,鄰居發現將傳送到請求節點多播地址(例如,如果 IPv6 地址是fe80::101:101那麼它將傳送到ff02::1:ff01:101) 在 IPv4 6over4 多播網路上的地址239.192.x.y,用 IPv6 地址的最後 16 位構建(因此在前面的例子中,它將是239.192.1.1).
其思路類似於 6over4,即使用 IPv4 網路作為物理鏈路來到達 IPv6 目標,但我們想克服請求多播支援的限制。在沒有鄰居發現機制的情況下,使用 ISATAP 的目標的 IPv4 地址被合併到 IPv6 地址中,更確切地說是介面識別符號中,其格式為0000:5efe:x:y,其中x和y是 IPv4 地址的 32 位。如您所見,這個解決方案沒有解決引入 IPv6 的問題,即 IPv4 地址的稀缺性。然而,這個解決方案在 IPv4 鏈路連線的不是主機,而是邊界上有 IPv6 雲的路由器的情況下更實用。在這種情況下,IPv4 網路中的主機想要以 IPv6 與屬於雲的主機通訊,必須配備潛在路由器列表 (PRL)。此時出現的問題是
- 如何獲取 PRL?
- 存在兩種不同的解決方案:前者是專有的,基於使用 DHCP;後者是標準的,基於使用 DNS。在後者中,對於具有以下格式的特定名稱的 DNS 查詢isatap.dominio.it,它將提供連線到查詢中指定的域的 IPv4 網路的 IPv6 路由器的 PRL。
- 應該將發往 IPv6 目標的報文傳送到哪個路由器?
- 對每個 PRL 路由器使用單播路由器發現,以便透過路由器通告獲得回覆。請記住,實際上,在通告路由器中,路由器還可以通告可以透過它們到達的 IPv6 網路列表(參見L=0標誌在ICMP 路由器通告的字首資訊選項中)。
通常,面向網路的隧道解決方案需要手動配置,封裝可以基於 IPv6 在 IPv4(協議型別 = 41)、GRE、IPsec 等。
從之前的解決方案中取得的最大進步來自這樣一個考慮:在新場景中,有一個完整的 IPv6 網路需要一個 IPv4 地址才能從 IPv6 雲中出來,不再是一個單獨的主機。然後,在 IPv6 字首中完成兩個地址之間的對映,而不是在介面識別符號中:為所有 IPv6 網路分配一個特殊的字首,該字首包含分配給面向雲的雙棧路由器的介面的 IPv4 地址。字首2002::/16標識正在使用 6to4 的 IPv6 站點:在接下來的 32 位中設定 IPv4 地址,並且還有 16 位可用於表示多個不同的子網,而介面識別符號則像其他 IPv6 用例中一樣獲得。在這個解決方案中,還有一個路由器具有特殊的作用,即6to4 中繼,它必須是 6to4 路由器的預設閘道器,以便將沒有剛才看到的 6to4 格式的報文轉發到全域性 IPv6。這個路由器的地址是192.88.99.1,這是一個任播地址:它被誰構思了 6to4,因為它被認為是在同一網路中有多個 6to4 中繼的場景,這將導致必須使用不同地址的問題。相反,由於任播地址透過路由協議以不同的方式處理,因此可以使用相同的地址,並提供負載平衡。
假設有兩個連線到 IPv4 雲的 IPv6 雲,並且雙棧路由器的介面對於連線到 IPv6 雲的介面,具有地址192.1.2.3對於網路 A,以及9.254.2.252對於網路 B。假設網路 A 中的主機 a 想要向網路 B 中的主機 b 傳送一個報文。從概述的配置和已經說過的話可以清楚地看到,存在於網路 A 中的主機將具有型別為2002:c001:02:03/48的地址,而存在於網路 B 中的主機將具有2002:09fe:02fc::/48的地址。從 a 到 b 的 IPv6 報文將封裝在一個 IPv4 報文中,該報文的目的地地址為9.254.2.252,從目的 IPv6 地址的字首中獲得:當報文到達該路由器時,它將被解封裝並根據包含網路 B 的雲的 IPv6 地址計劃轉發。
它與 6to4 非常相似,除了封裝是在包含在 IPv4 報文中的 UDP 段內完成的,而不是簡單地封裝在 IPv4 中。這樣做是為了克服 6to4 的限制,即穿越 NAT:由於在 6to4 中,封裝 IPv4 報文內沒有 2 級段,因此 NAT 無法工作。
6to4 解決方案的問題是它不夠通用:你被繫結到使用2002::/16地址,你不能使用通常的全域性單播。在隧道代理解決方案中,由於不再能夠從 IPv6 字首中推斷出應該將報文傳送到哪個端點,因此使用了一個伺服器,該伺服器在給定一個通用的 IPv6 地址後,提供了要聯絡的端點隧道的地址。實現隧道代理的路由器稱為隧道伺服器,而提供對映的伺服器稱為隧道代理伺服器。隧道像 6to4 一樣建立,因此 IPv6 在 IPv4 內:如果存在穿越 NAT 的問題,你也可以考慮使用 Teredo 的方法,透過封裝在 UDP 內,然後封裝在 IPv4 內。
需要配置隧道代理伺服器:隧道資訊控制(TIC)用於將有關給定隧道伺服器可達網路的資訊從正在配置的隧道伺服器轉發到隧道代理伺服器。隧道建立協議(TSP)用於向隧道代理伺服器請求資訊。同樣,你可以為全域性 IPv6 網路有一個預設閘道器。總之,具有此配置的路由器,當一個報文到達時,可以
- 如果它與路由表中的條目匹配,則直接轉發它(經典情況);
- 詢問隧道代理伺服器以檢視它是否是一個需要隧道的地址;
- 如果隧道代理伺服器的響應為否定,則將其傳送到全域性 IPv6 預設閘道器。
- 它是一個集中式解決方案,因此隧道代理伺服器是一個單點故障。
- 它使控制計劃變得複雜。
- 如果此伺服器用於互連不同的網路,即使這些網路屬於不同的提供商,也會出現其管理責任的問題。
- 它比 6to4 更靈活,因為它允許使用所有全域性單播地址。

目標是遷移大型提供商的網路,以便網路邊緣的 IPv4 和/或 IPv6 雲可以使用 IPv6 骨幹網進行互操作。常見的場景是一個使用者想要透過提供商的 IPv6 網路連線到 IPv4 目標。
所有可用的選項都使用 NAT。NAT 的使用有點逆潮流而行,因為 IPv6 的目標之一是避免在網路中使用 NAT,因為 NAT 帶來了許多問題(報文在傳輸中的更改,對等網路問題等)。但是,這些解決方案基於 NAT 事實上帶來了許多優點:NAT 在網路中廣泛傳播,它們的優缺點是已知的,可能在穿越 NAT 時出現問題的應用程式是已知的;因此,總的來說,優勢在於迄今為止獲得的巨大經驗。
在基於 NAT 的解決方案中,有三個主要元件
- 客戶機房裝置(CPE):它是客戶邊緣的路由器,就在提供商的網路之前;
- 地址族轉換路由器(AFTR):它是IPv6 隧道集中器,即 IPv6 隧道的末端的裝置;
- NAT44/NAT64:它是用於將 IPv4/IPv6 地址轉換為 IPv4 地址的 NAT。
- NAT64;
- 雙棧精簡版 (DS-Lite): NAT44 + 4-over-6 隧道;
- 雙棧精簡版地址+埠 (DS-Lite A+P): 帶有預配置埠範圍的 DS-Lite;
- NAT444:CGN + CPE NAT44,即當家庭使用者從電話公司獲得服務時,在其家庭網路中新增 NAT;從家庭網路發出的每個資料包都會進行兩次地址轉換;
- 運營商級 NAT (CGN):大規模 NAT44,即電話公司用來將數十萬個(使用者)私有地址對映到可用的有限公共地址的 NAT。
對於面向移動裝置的大型網路遷移,選擇 NAT64 解決方案。
為了遷移到 IPv6,在網路邊緣保持 IPv4 相容性,一些電話運營商正在計劃大規模遷移到 DS-Lite,因為它經過充分測試,並且已經有幾種相容裝置上市。
由於缺乏經驗,A+P 解決方案目前還沒有被認真考慮。

- IPv6 專用使用者型別www.example.com輸入到他的瀏覽器中,由於是 IPv6,他向提供商的 DNS64 傳送 AAAA 查詢。假設www.example.com具有 IPv4 地址 '20.2.2.2'。
- DNS64 在沒有名稱解析的情況下,需要將查詢傳送到上級 DNS,假設在 IPv4 網路中。
- 在最佳情況下,DNS64 將 AAAA 查詢傳送到上級 DNS,並獲得型別為 AAAA(即 IPv6)的回覆,它會原樣將回復傳輸回主機(透過 IPv4 資料包傳送需要將名稱解析為 IPv6 地址的 DNS 查詢是完全可能的)。
- 在最壞的情況下,上級 DNS 不支援 IPv4,因此會回覆 '名稱錯誤';DNS64 再次傳送查詢,但這次是型別 A,然後它將獲得正確的回覆。此回覆將被轉換為 AAAA 並傳輸回主機。在傳輸給主機的回覆中,最後 32 位與上級 DNS 在型別 A 記錄中傳送的 32 位相同,而其他 96 位完成 IPv6 地址;因此最終地址將是 '64:FF9B::20.2.2.2'。
- 現在主機已準備好建立 TCP 連線到www.example.com.
- NAT64 開始發揮作用:它將來自主機的 IPv6 資料包轉換為 IPv4,並對來自 20.2.2.2 的資料包執行反向操作。
- 在這種情況下,沒有隧道:IPv6 頭只是被 IPv4 頭替換,反之亦然。
- IPv6 專用主機並不知道目標地址與 IPv4 地址相關聯。
- NAT64 不僅能夠將 IPv6 地址轉換為 IPv4 地址,而且在某種程度上使網路相信有 232 個 IPv6 地址可用,因為來自主機到 NAT64 的每個資料包都將具有 '64:FF9B::20.2.2.2',字首為 '64:FF9B/96',作為目標地址。
- 提供商的網路(即 NAT64 和 DNS64 所在的網路)是 IPv6 原生的,因此提供商網路中的主機可以直接與另一個支援 IPv6 的主機進行通訊,而根本不涉及 NAT64。
- '64:FF9B/96' 是專門為此轉換技術標準化的定址空間,分配給 NAT64,但網路管理員可以根據需要更改它。請注意,網路管理員需要配置路由,以便每個具有該字首的資料包都將傳送到 NAT64,並且需要配置 NAT64,以便它將每個具有該字首的 IPv6 資料包轉換為 IPv4,並將其轉發到 IPv4 雲中。
- NAT 的存在會帶來一個典型問題:NAT 後面的主機不容易從外部訪問。
- 通常,當 DNS 沒有地址解析時,它根本不回覆,而是傳送 '名稱錯誤';這會導致 DNS64 等待超時的時間延長,當超時到期時,它會發送型別 A 的查詢。
- 如果使用者想要直接輸入 IPv4 地址,此解決方案將不起作用:使用者始終需要指定目標的名稱。

雙棧精簡版 (DS-Lite) 解決方案包括簡化 CPE,將 NAT 和 DHCP 功能移到提供商網路的邊緣,即到充當 AFTR 和 CGN-NAT44 的裝置。
- 提供商的 DHCP 伺服器為每個 CPE 的每個主機分配一個在提供商網路內唯一的 IPv6 地址。
- 當用戶需要傳送 IPv4 資料包時,需要進行隧道操作,以便將 IPv4 資料包封裝到 IPv6 資料包中,因為提供商的網路是 IPv6 專用的。因此,當 CPE 接收到 IPv4 資料包時,它需要將其隧道化到 IPv6 資料包中,以便能夠將其傳送到 AFTR,然後是 IPv4 雲;因此,該場景由提供商的 IPv6 網路中 AFTR 與多個使用者 CPE 之間的大量隧道操作組成。特別是,CPE 和 AFTR 之間的資料包的源 IPv6 地址將是 AFTR 的地址,目標 IPv4 地址將是 IPv4 網路中的目標地址。
- AFTR 在刪除 IPv6 頭後,將其傳送到 NAT44,NAT44 會將 IPv4(私有)源地址替換為 NAT 將接收與該流關聯的資料包的 IPv4 地址。
DS-Lite 的主要優勢是顯著減少了提供商的公共地址數量。
提供商網路中是否存在任何重複的 IPv4 地址?不,因為 NAT44 直接將主機的 IPv4 地址轉換為可用的公共 IPv4 地址。如果存在重複的私有 IPv4 地址,NAT 將會遇到歧義問題。
- IPv4 主機無法聯絡 IPv6 目標→ IPv6 目標只能由 IPv6 主機訪問。相反,IPv6 主機可以傳送和接收來自 IPv6 節點的資料包,而無需透過提供商的 AFTR。
- 某些型別的應用程式在這種情況下無法執行:NAT 無法由使用者管理,因為它不再位於 CPE 上,這使得無法執行一些常見操作,例如開啟/關閉特定應用程式所需的埠。

雙棧精簡版地址+埠 (DS-Lite A+P) 解決方案仍然包含提供商的 IPv6 專用網路,但 NAT 被移到 CPE 上,以便使用者可以根據需要對其進行配置。
與 DS-Lite 一樣,從 CPE 發出的 IPv4 資料包仍然需要進行隧道化,因為提供商的網路是 IPv6 專用的。
每個 CPE 上的 NAT 需要一個公共 IPv4 地址,這是透過允許複製公共 IPv4 地址來解決的,並且基於埠來區分 CPE。事實上,每個 CPE 使用一個特定的埠範圍,AFTR 瞭解每個 CPE 使用的埠範圍,能夠區分來自特定 CPE 或傳送到特定 CPE 的流,儘管有幾個 CPE 具有相同的公共 IPv4 地址。
此解決方案與 DS-Lite 類似,但私有 IPv4 地址空間在終端使用者控制下的程度更高,因為 NAT 位於使用者 CPE 上,使用者可以對其進行配置,即使有一些限制:他無法開啟和使用不在其範圍內的埠。此方法允許節省 IPv4 地址(但與 DS-Lite 相比仍然較少)。
此解決方案在義大利基本上是非法的,因為埠號沒有被記錄下來,如果發生攻擊,將無法追蹤到攻擊者。
主要目標是在全球網路上實現 IPv6 流量,同時不影響現有的 IPv4 網路,該網路已經運行了 20 多年,目前執行良好。在全球範圍內遷移到 IPv6 並徹底改變現有的 IPv4 網路,其人力和技術成本是無法承受的。
6 Provider Edge (6PE) 解決方案的目標是透過 MPLS 骨幹網將 IPv6 雲互連。6PE 要求運營商的網路透過 MPLS 工作。在這種情況下,提供商的邊緣由使用者 CPE 遇到的第一臺路由器表示。
- 保持網路核心不變(不排除將來更改的可能性)。
- 在提供商網路的邊緣新增 IPv6 支援。
- 透過 MPLS/BGP 傳輸 IPv6 路由資訊,就像在 VPN 中一樣:
 計算機網路技術和服務/VPN#第 3 層:BGP。
計算機網路技術和服務/VPN#第 3 層:BGP。

主要需求是擁有一個 MPLS 核心網路。
在圖中
- MPLS 核心網路是由 PE-1、P-1、P-2、PE-2 組成的;
- 兩側裝置 PE-1 和 PE-2 部分“沉浸”在 MPLS 網路中;
- CE 和 PE 之間的鏈路可以被認為是為家庭使用者提供 ADSL 連線的鏈路。
6PE 的思路是採用一個完全工作的核心網路,該網路能夠透過 MPLS 傳輸 IPv4 資料包,並在提供商的邊緣路由器 (PE) 上新增 IPv6 支援僅。事實上,一旦資料包被封裝成 MPLS 資料包,中間裝置就不再關心所包含資料包的型別,而是隻關心標籤,該標籤允許它們區分要路由到的 LSP。
事實上,在 PE 上需要進行進一步的更新,以便新增 MG-BGP 支援,該協議允許傳輸和通訊 IPv4 和 IPv6 路由。
那麼,這種解決方案的優勢在於只需要更新 PE,而不需要更新所有中間路由器:畢竟,這是一個提供商可以在低成本下管理的操作。
- CE-3 宣傳它能夠到達 IPv6 網路“2001:3::/64”。
- PE-2 也收到了此資訊。
- PE-2 將此資訊傳送給網路中的所有 PE,說明它能夠透過下一個躍點“FFFF:20.2.2.2”到達“2001:3::/64”,但它的介面是 IPv4(這是因為如果 IPv6 路由被賦予 IPv6 下一個躍點,則需要提供 IPv6 下一個躍點)。
- PE-1 收到此資訊。
- PE-1 將收到的資訊傳送給連線到它的所有路由器,包括家庭 CE,說明它能夠到達網路“2001:3::/64”。
- 如果 PE-1 和地址“20.2.2.2”之間的 MPLS 路徑尚不存在,則使用傳統的 MPLS 機制(即 LDPv4 訊號協議)來建立此路徑。

為了路由 IPv6 資料包,使用兩個標籤
| LDP/IGPv4 外部標籤到 PE-2 | MP-BGP 內部標籤到 CE-3 | IPv6 資料包到 IPv6 目的地 |
- MP-BGP 標籤(內部):它標識目的地 PE 需要將資料包傳送到的目的地 CE;
- LDP/IGPv4 標籤(外部):它標識 MPLS 網路上兩個 PE 之間的 LSP。
假設網路“2001:1::/64”中的主機想要傳送一個數據包到網路“2001:3::/64”中的主機
- 資料包到達 CE-1;
- CE-1 知道網路“2001:3::1/64”存在,並將資料包傳送到 PE-1;
- PE-1 在資料包前面放置兩個標籤:內部標籤和外部標籤;
- PE-1 將資料包傳送到 P-1,P-1 將資料包傳送到 P-2;
- P-2 是倒數第二個躍點,它從資料包中刪除外部標籤(倒數第二個標籤彈出),並將資料包傳送到 PE-2;
- PE-2 刪除內部標籤並將資料包傳送到 CE-3;
- CE-3 將資料包轉發到網路“2001:3::/64”中的目的地。
- PE 路由器必須是雙棧並支援 MP-BGP,而中間路由器不需要任何更改。
- 此解決方案為客戶提供本機 IPv6 服務,無需更改 IPv4 MPLS 核心網路(需要最小的運營成本和風險)。
- 只要部署的 IPv6 雲很少,此解決方案就能擴充套件。
人們對安全問題的經驗很少,因為 IPv6 還沒有得到廣泛使用→ IPv6 可能仍然存在未被發現的安全漏洞,這些漏洞可能會被攻擊者利用。此外,在遷移階段,主機需要同時開啟兩個埠,一個用於 IPv4,另一個用於 IPv6→ 需要保護這兩個埠免受外部攻擊。
- 使用 SYN 泛洪的 DDoS 攻擊
主機介面可以有多個 IPv6 地址→ 它可以生成多個 TCP SYN 請求,每個請求都使用不同的源地址,以使伺服器開啟多個未關閉的 TCP 連線,從而使伺服器的記憶體飽和。
- 偽造的路由器通告訊息
主機可能會開始傳送“路由器通告”訊息,以宣傳虛假的網路字首→ 鏈路中的其他主機將開始使用源地址中錯誤的網路字首傳送資料包。