
路由協議和架構/路由演算法
| 以下介紹的路由演算法假設它們在基於網路地址路由的網路上執行。 |
路由演算法是協作型別的一種流程,負責在每個中間節點上決定到達目的地的方向。
- 它確定每個節點可達目的地。
- 它生成關於本地網路可達性的資訊:路由器通知其鄰居路由器本地網路存在,並且可以透過它到達。
- 它接收關於遠端網路可達性的資訊:鄰居路由器通知路由器遠端網路存在,並且可以透過它到達。
- 它傳播關於遠端網路可達性的資訊:路由器通知其他鄰居路由器遠端網路存在,並且可以透過它到達。
- 它根據某些標準以協作方式與其他節點一起計算最佳路徑(下一跳)。
- 必須建立一個度量:一條路徑可能是基於一個度量最好的路徑,但不是基於另一個度量。
- 標準必須在網路中的所有節點之間一致,以避免迴圈、黑洞等。
- 演算法必須自動執行,以避免人工配置錯誤並有利於可擴充套件性。
- 它將本地資訊儲存在每個節點的路由表中:路由演算法不需要了解網路的整個拓撲結構,它只關心構建正確的路由表。
- 理想路由演算法的特點
- 簡單實現:錯誤更少,易於理解等。
- 輕量級執行:路由器在執行演算法時應儘可能少地消耗資源,因為它們的 CPU 和記憶體有限。
- 最優:計算出的路徑應根據選擇的度量是最優的。
- 穩定:只有在拓撲結構或成本發生變化時才應該切換到另一條路徑,以避免路由震盪,即首選路由頻繁變化,隨之而來的瞬態週期過長。
- 公平:它不應偏袒任何特定的節點或路徑。
- 健壯:它應該能夠自動適應拓撲結構或成本變化
- 故障檢測:它不應依賴外部元件來檢測故障(例如,如果故障發生在集線器之外,則無法在物理層檢測到它)。
- 自動穩定:在網路發生變化的情況下,它應該收斂到一個解決方案,而無需任何外部干預(例如,明確的手工配置)。
- 拜占庭容錯:它應該識別並隔離由於故障或惡意攻擊而傳送虛假資訊的鄰居節點。
網際網路沒有實現拜占庭容錯,但它基於信任→故障和惡意行為需要人工干預。
- 路由演算法分類
- 非自適應演算法(靜態):它們獨立於網路狀況做出決策
- 靜態路由(或固定目錄路由)
- 隨機遊走
- 泛洪,選擇性泛洪
- 自適應演算法(動態):它們瞭解有關網路的資訊以更好地做出決策
- 集中式路由
- 隔離路由:熱土豆,反向學習
- 分散式路由:距離向量,鏈路狀態
- 分層演算法:它們允許路由演算法在廣泛的基礎設施上擴充套件。
度量是衡量一條路徑好壞的指標,它透過將物理量(例如距離、傳輸速度)或它們的組合轉換為數值形式(成本)來獲得,以便選擇成本最低的路徑作為最佳路徑。
對於所有型別的流量,不存在最佳度量:例如,頻寬適合檔案傳輸流量,而傳輸延遲適合即時流量。 度量的選擇可以從 IP 資料包中的“服務型別”(TOS)欄位確定。
- 問題
- (非)最佳化:路由器的主要任務是轉發使用者流量,而不是花時間計算路徑→最好優先選擇即使沒有完全最佳化,也不會影響網路主要功能並且不會表現出使用者可以感知到的問題的解決方案
- 複雜度:組合的標準越多,演算法就越複雜,執行時所需的計算資源就越多。
- 穩定性:基於鏈路可用頻寬的度量太不穩定,因為它取決於瞬時流量負載,而瞬時流量負載在時間上變化很大,並且可能導致路由震盪。
- 不一致:網路中節點採用的度量必須一致(對於每個資料包),以避免迴圈的風險,即資料包在使用不同衝突度量的兩個路由器之間“彈跳”。
現代路由演算法總是“活躍的”:它們不斷交換服務訊息以自動檢測故障。 但是,它們不會更改路由表,除非檢測到狀態更改
- 拓撲結構更改:鏈路故障,新增新目的地。
- 成本更改:例如,一條 100 Mbps 鏈路升級到 1 Gbps。
狀態更改會導致瞬態階段:分散式系統中的所有節點不能同時更新,因為變化以有限的速度在整個網路中傳播→在瞬態期間,網路中的狀態資訊可能不一致:某些節點已經有了新的資訊(例如,檢測到故障的路由器),而其他節點仍然擁有舊的資訊。
並非所有狀態更改對資料流量的影響都相同
- 正狀態更改:瞬態的影響是有限的,因為網路可能只是暫時處於次優狀態
- 一條路徑的成本變得更低:一些資料包可能仍然按照現在變得不太方便的舊路徑前進。
- 添加了新的目的地:由於通往它的路徑上的黑洞,該目的地可能看起來不可到達。
- 負狀態更改:瞬態的影響對使用者來說更為嚴重,因為它也會干擾不應該受故障影響的流量
- 連結故障發生:並非所有路由器都已瞭解舊路徑不再可用→資料包可能開始在備用連結上“來回彈跳”,導致備用連結飽和(路由迴圈);
- 路徑成本變差:並非所有路由器都已瞭解舊路徑不再方便→類似於故障情況(路由迴圈)。
一般而言,在瞬態期間,有兩個常見問題會影響路由演算法:黑洞和路由迴圈。
黑洞定義為:即使存在至少一條可以到達特定目的地的路徑,路由器也無法得知任何路徑(暫未得知)。
- 影響
對資料流量的影響僅限於指向相關目的地的資料包,這些資料包會被丟棄,直到節點更新其路由表並獲取有關如何到達目的地的資訊。指向其他目的地的流量完全不受黑洞影響。
路由迴圈定義為從路由角度來看的迴圈路徑:路由器將資料包傳送到一條鏈路上,但由於路由表不一致,連結另一端路由器將資料包傳送回原路由器。
- 影響
指向相關目的地的資料包開始在鏈路上“來回彈跳”(彈跳效應)→連結變得飽和→穿越該連結的指向其他目的地的流量也會受到影響。
備用路由是一個主要用於基於層次結構組織的電話網路的概念:每個交換機透過主路由連線到上級交換機,並透過備用路由連線到另一個上級交換機→如果主路由出現故障,備用路由可以立即投入使用,無需任何瞬態過程。
資料網路則基於網狀拓撲結構,路由器以多種方式相互連線→無法預見網路中所有可能的故障以預先安排備用路徑,但當出現故障時,路由演算法優選自動計算出備用路徑(即使計算步驟需要瞬態過程)。
現代網路中的備用路由仍然可以應用
- 透過ADSL連線到網際網路的公司,當ADSL線路斷開時,可以透過切換到HiperLAN技術(無線)的備用路由來保持連線;
- 網際網路骨幹網現在掌握在電話公司手中,這些公司根據電話網路的標準對其進行了建模→其組織結構具有足夠的層次性,可以預先安排備用路由。
使用網路地址進行路由時,所有指向目的地的資料包都遵循相同的路徑,即使存在備用路徑→最好將部分流量沿備用路徑傳送,即使備用路徑的成本更高,也不要使演算法選擇的路徑飽和。
多路徑路由也稱為“負載共享”,是一種流量工程功能,旨在將指向同一目的地的流量分佈到多條路徑(如果可用),在路由表中為每個目的地建立多個條目,以便更有效地使用網路資源。
僅當備用路徑的成本 不明顯大於最小成本主路徑的成本 時,才會使用備用路徑



流量與路徑成本成反比分佈。例如在這種情況下

路由器可以決定以66%的機率將資料包沿主路徑傳送,以33%的機率沿備用路徑傳送。
- 問題
對於給定的資料包,每個路由器會自主決定沿哪條路徑轉發→路由器之間可能做出不一致的決定,導致資料包進入路由迴圈,並且由於轉發通常基於會話,因此該資料包將永遠無法退出迴圈

只有當備用路徑的成本 恰好等於主路徑的成本 時,才會使用備用路徑 ()。


流量在兩條路徑上均等分配(50%)。
- 問題
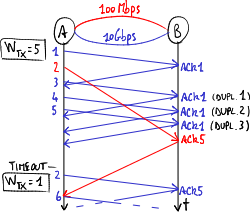
如果第一個資料包走的是慢速路徑,而第二個資料包走的是快速路徑,TCP 機制可能會導致整體效能下降。
- 等成本多路徑路由引起的問題。
-
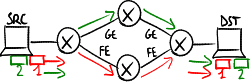 TCP 排序問題。
TCP 排序問題。 -
 傳輸速率下降。
傳輸速率下降。


- TCP 排序問題:資料包可能亂序到達:第二個資料包在第一個資料包之前到達目的地 → 用於排序序號的處理過程會佔用接收端的計算資源;
- 傳輸速率下降:如果第一個資料包的確認包(ACK)到達太晚,源端會認為第一個資料包丟失了 → 當 3 個重複(累積)ACK 到達且超時時間到期時,TCP 滑動視窗機制 會啟動
- 快速重傳:源端會不必要地再次傳輸資料包 → 資料包會重複;
- 快速恢復:源端會認為網路擁塞 → 它會透過限制傳輸視窗來降低資料包傳送速度:將閾值設定為當前擁塞視窗值的一半,並使擁塞視窗從值 1 重新開始(即一次只發送一個數據包,並在傳送下一個資料包之前等待其 ACK)。
標準
[edit | edit source]真正的多路徑路由實現會將流量拆分,使得到達同一目的地的流量走相同的路徑。
- 基於流的:每個傳輸層會話由五元組標識
- <源 IP 地址>
- <目標 IP 地址>
- <傳輸層協議型別>(例如 TCP)
- <源埠>
- <目標埠>
路由器會儲存一個表,將會話識別符號對映到輸出埠
- 由於支援的各種資料包格式(VLAN、MPLS 等),從資料包中提取構成會話 ID 的欄位很繁瑣;
- 對於分片 IP 資料包,傳輸層埠資訊不可用;
- 在會話 ID 表中查詢五元組很繁瑣;
- 通常 TCP 連線關閉不是“優雅退出”,也就是說 FIN 和 ACK 資料包不會被髮送 → 會話 ID 表中的條目不會被清除 → 需要一個執行緒來定期清理舊條目,方法是檢視它們的 timestamp;
- 基於資料包的:路由器會將具有偶數(目標或源或兩者)IP 地址的資料包傳送到一條路徑,而將具有奇數 IP 地址的資料包傳送到另一條路徑 → 雜湊操作非常快。
- 問題
到達同一目的地的流量不能同時使用兩條路徑 → 如果有大量流量到達某個特定目的地(例如,兩個伺服器之間的夜間備份),就會出現問題。
非自適應演算法
[edit | edit source]靜態路由
[edit | edit source]網路管理員會在每臺路由器上手動配置其路由表。
- 缺點
如果網路發生變化,則需要手動更新路由表。
- 應用
靜態路由主要用於網路邊緣的路由器

- 邊緣路由器不允許 傳播路由資訊到骨幹網:核心路由器會阻止來自邊緣的所有廣告,否則使用者可能會宣傳一個地址與現有網路(例如 google.com)相同的網路,並將他重定向到指向該網路的部分流量。
由於使用者不能宣傳自己的網路,如何才能從外部訪問它們? ISP 瞭解其出售給使用者的網路所使用的地址,必須配置核心路由器,使其即使沒有本地連線也能將這些網路廣告給其他路由器; - 邊緣路由器不允許 接收來自骨幹網的路由資訊:邊緣路由器通常透過單個鏈路連線到核心路由器 → 一個全域性預設路由足以訪問整個網際網路。
隨機漫步
[edit | edit source]當資料包到達時,路由器會隨機選擇一個埠(但不是接收資料包的埠),並將資料包傳送到該埠。
- 應用
當資料包到達目的地的機率很高時,它很有用
- 對等網路(P2P):用於內容查詢;
- 感測器網路:傳送訊息應該是低功耗操作。
泛洪
[edit | edit source]當資料包到達時,路由器會將資料包傳送到所有埠(但不是接收資料包的埠)。
資料包可能有一個“跳數”欄位,用於將泛洪限制到網路的一部分。
- 應用
- 軍事應用:在攻擊情況下,網路可能會損壞 → 資料包能夠到達目的地至關重要,即使這會導致大量重複流量;
- 鏈路狀態演算法:每個路由器在接收到來自鄰居的網路地圖後,必須將其傳播給其他鄰居:
 A4. 鏈路狀態演算法#泛洪演算法.
A4. 鏈路狀態演算法#泛洪演算法.
當資料包到達時,路由器首先檢查它是否已在過去收到並泛洪。
- 舊資料包:它會丟棄它;
- 新資料包:它會儲存並將其傳送到所有埠(但接收到的埠除外)。
每個資料包透過傳送者識別符號(例如源 IP 地址)和序列號來識別
- 如果傳送者從網路斷開連線或關閉,當它再次連線時,序列號將從頭開始 → 路由器將所有接收到的資料包視為舊資料包;
- 序列號編碼在有限數量的位上 → 應選擇序列號空間,以最大程度地減少錯誤地識別為舊資料包的新資料包。
- 線性空間
如果選擇性泛洪用於少量控制訊息,則可以容忍它
- 當序列號達到最大可能值時,會發生溢位錯誤;
- 舊資料包:序列號低於當前序列號;
- 新資料包:序列號大於當前序列號。
- 迴圈空間
它解決了序列號空間耗盡問題,但如果資料包到達的序列號與當前序列號相差太遠,它就會失敗
- 當序列號達到最大可能值時,序列號將從最小值重新開始;
- 舊資料包:序列號位於當前序列號之前的半部分;
- 舊資料包:序列號位於當前序列號之後的半部分。
- 棒棒糖空間
空間的前半部分是線性的,後半部分是迴圈的。
所有路由器都連線到一個稱為 **路由控制中心** (RCC) 的集中式控制核心:每個路由器都告訴 RCC 它的鄰居是誰,RCC 使用這些資訊來建立網路地圖,計算路由表並將其傳達給所有路由器。
- 優點
- 效能:路由器不需要具有很高的計算能力,所有計算都集中在一個裝置上;
- 除錯:網路管理員可以從單個裝置獲取整個網路的地圖,以檢查其正確性;
- 維護:智慧集中在控制中心 → 更新演算法只需更新控制中心即可。
- 缺點
- 容錯性:控制中心是單點故障 → 控制中心的故障會影響整個網路;
- 可擴充套件性:網路包含的路由器越多,控制中心的負擔就越重 → 它不適合網際網路等廣域網路。
- 應用
電話網路中使用類似的原理。
沒有控制中心,但所有節點都是對等的:每個節點自主地決定其路徑,無需與其他路由器交換資訊。
- 優點和缺點
它們實際上是集中式路由的相反。
每個節點根據資料包源地址學習網路資訊: ![]() 本地網路設計/A3. 中繼器和網橋#透明網橋。
本地網路設計/A3. 中繼器和網橋#透明網橋。
- 它僅在“健談”的節點上執行良好;
- 當最佳路徑不再可用時,很難實現切換到備用路徑的需要;
- 很難檢測到目標變得無法訪問 → 需要一個特殊的計時器來刪除舊條目。
分散式路由使用“對等”模型:它利用了集中式路由和隔離路由的優勢
- 集中式路由:路由器參與有關連線性的資訊交換;
- 隔離路由:路由器是等效的,不存在“更好”的路由器。
- 應用
現代路由協議使用兩種主要的分散式路由演算法
- 鄰居
- LS:需要“hello”協議;
- DV:透過 DV 本身瞭解它的鄰居。
- 路由表
DV 和 LS 建立相同的路由表,只是以不同的方式計算,並且具有不同的瞬態持續時間(和行為)
- LS:路由器協作以保持網路地圖最新,然後每個路由器計算自己的生成樹:每個路由器都知道網路的拓撲結構,並且知道到達目標的精確路徑;
- DV:路由器協作以計算路由表:每個路由器只知道它的鄰居,並且信任它們來確定到達目標的路徑。
- 簡單性
- DV:易於實現的單個演算法;
- LS:包含許多不同的元件。
- 除錯
LS 中更好:每個節點都有網路地圖。
- 記憶體消耗 (在每個節點中)
它們可以被認為是等效的
- LS:每個 LS 有 個鄰接關係 (Dijkstra:);
- DV:每個 個 DV 有 個目標 (Bellman-Ford:)。




- 流量
LS 中更好:鄰居問候包比 DV 小得多。
- 收斂
LS 中更好:故障檢測更快,因為它基於以高頻率傳送的鄰居問候包。