
路由協議和架構/基於軟體的包過濾
能夠解析資料包中欄位的軟體,在各種應用程式中執行在積體電路或微處理器上。
- 交換機: 學習演算法基於幀源和目標 MAC 地址,幀轉發基於目標 MAC 地址;
- 路由器: 資料包轉發基於源和目標 IP 地址;
- 防火牆: 如果與資料包欄位匹配的規則,則會丟擲相關的過濾操作(例如,丟棄);
- NAT: 它在傳輸中的每個資料包之間轉換私有和公有 IP 地址以及 TCP/UDP 埠;
- URL 過濾: 它阻止來自/到黑名單中網站 URL 的 HTTP 流量;
- 協議棧: 作業系統將資料包傳遞到適當的網路層堆疊(例如 IPv4 或 IPv6),然後資料包傳遞到適當的傳輸層堆疊(例如 TCP 或 UDP),最後基於識別會話的五元組,資料包透過正確的套接字提供給應用程式;
- 資料包捕獲: 用於流量捕獲的應用程式(例如 Wireshark、tcpdump)可以設定過濾器以減少捕獲的資料包數量。
包過濾系統的典型架構
[edit | edit source]
- 核心級元件
- 網路竊聽器: 它攔截來自網絡卡的資料包並將它們傳遞給一個或多個[1]過濾堆疊;
- 資料包過濾器: 它只允許滿足捕獲應用程式指定的過濾器的包透過,從而提高捕獲效率: 不必要的資料包立即被丟棄,只有較少數量的資料包被複制到核心緩衝區;
- 核心緩衝區: 它在資料包被傳遞到使用者層之前儲存資料包;
- 核心級 API: 它為使用者層提供原語,通常ioctl系統呼叫,用於訪問底層。
- 使用者級元件
- 使用者緩衝區: 它將資料包儲存到使用者應用程式的地址空間;
- 使用者級庫(例如 libpcap、WinPcap): 它匯出與核心級 API 提供的原語相對映的函式,並提供高階編譯器以動態建立要注入資料包過濾器的偽彙編程式碼。
主要的包過濾系統
[edit | edit source]CSPF
[edit | edit source]卡內基梅隆大學/斯坦福大學資料包過濾器(CSPF,1987)是第一個資料包過濾器,它與其他協議棧並行實現。
它引入了了一些關鍵改進
- 核心級實現: 由於避免了核心空間和使用者空間之間上下文切換的成本,處理速度更快,儘管更容易破壞整個系統;
- 資料包批處理: 核心緩衝區不會立即將到達應用程式的資料包傳遞,而是等待儲存一定數量的資料包,然後將它們一起復制到使用者緩衝區以減少上下文切換次數;
- 虛擬機器: 過濾器不再是硬編碼的,而是使用者級程式碼可以在執行時例項化一段偽組合語言程式碼,指定過濾操作以確定資料包是否可以透過或必須被丟棄,以及資料包過濾器中的虛擬機器,實際上由switch case在所有可能的指令上,模擬一個處理器,該處理器解釋每個傳輸資料包的程式碼。
BPF/libpcap
[edit | edit source]伯克利資料包過濾器(BPF,1992)是第一個認真實現的資料包過濾器,歷史上被 BSD 系統採用,至今仍在使用,與使用者空間的libpcap庫相結合。
- 架構
- 網路竊聽器: 它整合在 NIC 驅動程式中,可以透過對捕獲元件的顯式呼叫來呼叫;
- 核心緩衝區: 它被分成兩個獨立的記憶體區域,以便核心級和使用者級程序可以獨立工作(第一個程序寫入,第二個程序讀取),而無需同步利用兩個 CPU 核心並行工作
- 儲存緩衝區是核心級程序寫入的區域;
- 保留緩衝區是使用者級程序讀取的區域。
NPF/WinPcap
[edit | edit source]WinPcap 庫(1998)最初由都靈理工大學開發,可以被認為是整個 BPF/libpcap 架構在 Windows 上的移植。
- 架構
- Netgroup 資料包過濾器(NPF): 它是核心級元件,包括
- 網路竊聽器: 它位於 NIC 驅動程式的頂部,註冊為標準協議(如 IPv4、IPv6)旁邊的新的網路層協議;
- 資料包過濾器: 虛擬機器是即時(JIT)編譯器: 它不是解釋程式碼,而是將其轉換為 x86 處理器本地指令;
- 核心緩衝區: 它被實現為迴圈緩衝區: 核心級和使用者級程序寫入同一個記憶體區域,核心級程序覆蓋使用者級程序已經讀取的資料→ 它優化了儲存資料包的空間,但是
- 如果使用者級程序讀取資料的速度太慢,核心級程序可能會覆蓋尚未讀取的資料(快取汙染)→ 需要兩個程序之間的同步: 寫入程序需要定期檢查包含當前讀取位置的共享變數;
- 記憶體區域在 CPU 核心之間共享→ 迴圈緩衝區效率較低;
- Packet.dll: 它在使用者層匯出與作業系統無關的函式,這些函式與核心級 API 提供的原語相對映;
- Wpcap.dll: 它是應用程式直接互動的動態連結庫
- 它為程式設計師提供用於訪問底層的高階庫函式(例如pcap_open_live(), pcap_setfilter(), pcap_next_ex()/pcap_loop());
- 它包括編譯器,該編譯器在給定使用者定義的過濾器(例如字串)時ip),建立要注入資料包過濾器的偽彙編程式碼(例如 "如果欄位 'EtherType' 等於 0x800 則返回 true")以供 JIT 編譯器使用;
- 它實現使用者緩衝區。
- 新功能
- 統計模式: 它在核心中記錄統計資料,無需任何上下文切換;
- 資料包注入: 透過網路介面傳送資料包;
- 遠端捕獲: 啟用遠端伺服器,捕獲資料包並將其本地交付。
- 效能最佳化技術的演變。
-
 傳統架構。
傳統架構。 -
 具有共享緩衝區的架構。
具有共享緩衝區的架構。 -
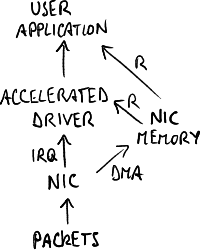 具有加速驅動的架構。
具有加速驅動的架構。



近年來,網路流量的增長速度快於計算機效能(記憶體、CPU)。 可以透過多種方式提高資料包處理效能
- 提高捕獲效能: 提高將資料傳遞到軟體的容量;
- 建立更智慧的分析元件: 僅將最有趣的資料傳遞到軟體(例如,URL 過濾器的 URL);
- 最佳化架構: 嘗試利用應用程式特性來提高效能。
- 分析資料 (WinPcap 3.0, 64 位元組長資料包)
- [49.02%] 網絡卡驅動程式和作業系統: 當進入網絡卡時,資料包需要花費大量時間才能到達捕獲堆疊
- 網絡卡透過 DMA 將資料包傳輸到其核心記憶體區域(這不會使用 CPU);
- 網絡卡向網絡卡驅動程式發出 \textbf{中斷} (IRQ),停止當前正在執行的程式;
- 網絡卡驅動程式將資料包從網絡卡記憶體複製到作業系統的核心記憶體區域(這會使用 CPU);
- 網絡卡驅動程式呼叫作業系統,將其控制權交給作業系統;
- 作業系統呼叫各種已註冊的協議棧,包括捕獲驅動程式;
- [17.70%] tap 處理: 捕獲驅動程式在捕獲堆疊開始時執行的操作(例如,接收資料包,設定中斷);
- [8.53%] 時間戳: 資料包與其時間戳相關聯;
- [3.45%] 資料包過濾器: 由於 JIT 編譯器,過濾成本成比例地降低;
- 雙重複制到緩衝區: 資料包越大,複製成本越高
- [9.48%] 核心緩衝區複製: 資料包從作業系統記憶體複製到核心緩衝區;
- [11.50%] 使用者緩衝區複製: 資料包從核心緩衝區複製到使用者緩衝區;
- [0.32%] 上下文切換: 由於資料包批處理,其成本微不足道。
在所有作業系統中,在某個輸入速率下,到達捕獲應用程式的資料包百分比不僅不再增加,而且會急劇下降,這是由於 **死鎖**: 中斷過於頻繁,以至於作業系統沒有時間從網絡卡記憶體讀取資料包並將它們複製到核心緩衝區中,以便將它們傳遞給應用程式 → 系統處於活動狀態並正在執行一些工作,但沒有執行一些有用的工作。
存在幾種解決方案來降低中斷成本
- **中斷緩解**(基於硬體):僅當接收一定數量的資料包時才觸發中斷(如果在一定時間內未達到最小閾值,則超時會避免飢餓);
- **中斷批處理**(基於軟體):當中斷到達時,作業系統會處理到達的資料包,然後以輪詢模式工作: 它會立即處理在此期間到達的後續資料包,直到沒有更多資料包,並且可以重新啟用網絡卡上的中斷;
- **裝置輪詢**(例如 BSD [Luigi Rizzo]):作業系統不再等待中斷,而是透過無限迴圈自動檢查網絡卡記憶體 → 由於 CPU 核心始終在無限迴圈中繁忙,因此此解決方案適合在真正需要高效能的情況下使用。
存在兩種解決方案來最佳化時間戳
- 近似時間戳: 實際時間僅有時會讀取,時間戳基於自上次讀取以來的時鐘週期數 → 時間戳取決於處理器時鐘頻率,並且處理器的時鐘頻率越來越高;
- 硬體時間戳: 時間戳直接在網絡卡中實現 → 資料包到達軟體時已帶有其時間戳。
包含核心緩衝區的核心記憶體區域對映到使用者空間(例如,透過nmap()) → 從核心緩衝區到使用者緩衝區的複製不再需要:應用程式可以直接從 **共享緩衝區** 讀取資料包。
- 實現
此解決方案已在 Luca Deri 的 nCap 中採用。
- 問題
- 安全性: 應用程式訪問核心記憶體區域 → 它可能會損壞系統;
- 定址: 核心緩衝區透過兩個不同的定址空間可見:核心空間中使用的地址與使用者空間中使用的地址不同;
- 同步: 應用程式和作業系統需要對共享變數(例如,資料讀寫位置)進行操作。
作業系統並非旨在支援大型網路流量,而是經過設計來執行記憶體使用量有限的使用者應用程式。 在到達捕獲堆疊之前,每個資料包都會儲存到作業系統的記憶體區域中,該區域是作為小型緩衝區的連結列表動態分配的(mbuf在 BSD 中,以及skbuf在 Linux 中) → 與用於儲存任何大小資料包的大型靜態分配緩衝區相比,迷你緩衝區的分配和釋放成本過於昂貴。
捕獲專用卡不再被作業系統識別,而是使用已整合到捕獲堆疊中的 **加速驅動程式**: 網絡卡將資料包複製到其核心記憶體區域,並且應用程式可以直接從該記憶體區域讀取,無需作業系統的介入。
- 實現
此解決方案已在 Luigi Rizzo 的 netmap 和 Luca Deri 的 DNA 中採用。
- 問題
- 應用程式: 其他協議棧(例如 TCP/IP 棧)消失 → 機器完全專用於捕獲;
- 作業系統: 需要對作業系統進行侵入性更改;
- 網絡卡: 加速驅動程式與網絡卡緊密繫結 → 無法使用其他網絡卡型號;
- 效能: 瓶頸仍然是 PCI 匯流排的頻寬;
- 時間戳: 由於軟體延遲,它並不精確。
處理轉移到核心空間,避免上下文切換到使用者空間。
- 實現
此解決方案已在 Intel 資料平面開發套件 (DPDK) 中採用,目的是透過 Intel 硬體上的軟體使網路裝置可程式設計。
- 問題
- 資料包批處理: 由於資料包批處理,上下文切換成本非常低;
- 除錯: 在使用者空間更容易;
- 安全性: 整個應用程式使用核心記憶體;
- 程式設計: 在核心空間編寫程式碼更困難。
處理直接由網絡卡執行(例如 Endace)
- 硬體處理: 它避免了 PCI 匯流排的瓶頸,限制了資料位移(即使效能提升有限);
- 時間戳精度: 沒有軟體延遲,並且基於 GPS → 這些網絡卡適用於跨地理區域廣泛的網路進行捕獲。
FFPF 提出了一種架構,該架構試圖透過增加 使用者空間中的並行性 來利用應用程式特性以更快地執行:捕獲應用程式是多執行緒的,並在多核 CPU 上執行。
硬體可以幫助並行化:網絡卡可以向作業系統註冊為多個介面卡,並且每個介面卡都是一個獨立的邏輯佇列,資料包會根據其分類從該佇列中退出,該分類是透過 **硬體過濾器** 執行的,基於其欄位(例如 MAC 地址、IP 地址、TCP/UDP 埠) → 多個軟體片段可以並行從不同的邏輯佇列讀取。
- 應用
- 接收端擴充套件 (RSS): 分類基於會話識別符號(五元組) → 屬於同一會話的所有資料包將進入同一個佇列 → 可以平衡 Web 伺服器上的負載:
 B8. 內容交付網路#伺服器負載均衡;
B8. 內容交付網路#伺服器負載均衡; - 虛擬化: 伺服器上的每個虛擬機器 (VM) 都有不同的 MAC 地址 → 資料包將直接進入正確的 VM,而不會被作業系統 (管理程式) 觸碰: C3. 軟體定義網路介紹#網路功能虛擬化.
- ↑ 每個捕獲應用程式都有自己的過濾堆疊,但它們都共享相同的網路監聽器。