
分子生物學導論/蛋白質的功能和結構
蛋白質最早由荷蘭化學家Gerhardus Johannes Mulder於1838年描述,並由瑞典化學家Jöns Jakob Berzelius命名。早期的營養學家,如德國的Carl von Voit,認為蛋白質是維持身體結構最重要的營養素,因為人們普遍認為“肉長肉”。
多肽鏈中的氨基酸透過肽鍵連線。一旦在蛋白質鏈中連線,單個氨基酸被稱為殘基,連線的碳、氮和氧原子系列被稱為主鏈或蛋白質骨架。肽鍵具有兩種共振形式,它們貢獻了一些雙鍵特徵並抑制了其軸線周圍的旋轉,因此α碳大致共面。肽鍵中的另外兩個二面角決定了蛋白質骨架所假設的區域性形狀。具有遊離羧基的一端稱為C端或羧基端,而具有遊離氨基的一端稱為N端或氨基端。
蛋白質、多肽和肽這些詞語有些模糊,含義可能重疊。蛋白質通常用於指代處於穩定構象的完整生物分子,而肽通常保留用於指代短的氨基酸寡聚體,這些寡聚體通常缺乏穩定的三維結構。然而,兩者之間的界限並不明確,通常在20-30個殘基附近。多肽可以指任何單個線性氨基酸鏈,通常與長度無關,但通常意味著缺乏定義的精氨酸構象。[1]


有22種標準氨基酸,但只有21種存在於真核生物中。在這22種中,20種直接由通用遺傳密碼編碼。人類可以從彼此或從其他中間代謝分子中合成這20種氨基酸中的11種。另外9種必須從飲食中攝取,因此被稱為必需氨基酸;它們是組氨酸、異亮氨酸、亮氨酸、賴氨酸、蛋氨酸、苯丙氨酸、蘇氨酸、色氨酸和纈氨酸。另外兩種,硒代半胱氨酸和吡咯賴氨酸,透過獨特的合成機制整合到蛋白質中。
每個α-氨基酸都由一個所有氨基酸型別中都存在的骨架部分和一個特定於每種殘基型別的側鏈組成。脯氨酸是這條規則的例外,其中氫原子被與側鏈的鍵取代。由於碳原子與四個不同的基團結合,因此它是手性的,但生物蛋白質中只存在一種異構體。然而,甘氨酸不是手性的,因為它的側鏈是一個氫原子。一個簡單的助記符來記憶正確的L-形式是“CORN”:當以H在前的視角觀察Cα原子時,殘基以“CO-R-N”的順時針方向排列。[2]
異構體
標準α-氨基酸,除甘氨酸外,都可以存在於兩種光學異構體中,稱為L或D氨基酸,它們是彼此的映象。雖然L-氨基酸代表了在核糖體翻譯過程中發現的所有蛋白質中的氨基酸,但D-氨基酸存在於一些由酶翻譯後修飾後產生的蛋白質中,這些修飾發生在翻譯後並易位到內質網,例如在錐形蝸牛等奇異的海生生物中。它們也是細菌肽聚糖細胞壁的豐富成分,並且D-絲氨酸可能在大腦中充當神經遞質。氨基酸構型的L和D約定不指氨基酸本身的光學活性,而是指理論上可以合成該氨基酸的甘油醛異構體的光學活性(D-甘油醛是右旋的;L-甘油醛是左旋的)。或者,(S)和(R)指定用於指示絕對立體化學。蛋白質中幾乎所有氨基酸在α碳處都是(S),其中半胱氨酸是(R),甘氨酸是非手性的。半胱氨酸很特殊,因為它的側鏈中第二個位置有一個硫原子,它的原子質量比連線到第一個碳的基團更大,而第一個碳連線到其他標準氨基酸的α碳,因此是(R)而不是(S)。[3]
兩性離子
氨基酸中發現的胺和羧酸官能團使其具有兩性性質。在被稱為等電點的特定pH值下,氨基酸沒有總電荷,因為質子化的氨基數量(正電荷)和去質子化的羧酸根數量(負電荷)相等。所有氨基酸都有不同的等電點。在等電點產生的離子同時具有正負電荷,被稱為兩性離子,這個詞來自德語單詞Zwitter,意思是“雌雄同體”或“混合體”。氨基酸可以在固體和水等極性溶液中以兩性離子的形式存在,但在氣相中不存在。兩性離子在其等電點處具有最小的溶解度,可以透過調節pH值使其達到特定的等電點來從水中沉澱出來,從而分離氨基酸。[4]
20種天然存在的氨基酸具有不同的物理和化學性質,包括它們的靜電電荷、pKa、疏水性、尺寸和特定官能團。這些性質在塑造蛋白質結構中起著重要作用。下表描述了氨基酸的主要特徵。
| 氨基酸 | 縮寫 | 備註 | |
|---|---|---|---|
丙氨酸 |
A | Ala | 非常豐富,用途廣泛。比甘氨酸更硬,但足夠小,只對蛋白質構象構成微小的空間限制。它表現得相當中性,可以位於蛋白質外部的親水區域和內部的疏水區域。 |
| 天冬醯胺或天冬氨酸 | B | Asx | 當兩種氨基酸都可能佔據一個位置時的佔位符。 |
半胱氨酸 |
C | Cys | 硫原子易與重金屬離子結合。在氧化條件下,兩個半胱氨酸可以連線在一起形成二硫鍵,形成氨基酸胱氨酸。當胱氨酸是蛋白質的一部分時,例如胰島素,其三級結構會得到穩定,這使得蛋白質更能抵抗變性;因此,二硫鍵在必須在惡劣環境中發揮作用的蛋白質中很常見,包括消化酶(例如,胃蛋白酶和胰凝乳蛋白酶)和結構蛋白(例如,角蛋白)。二硫鍵也存在於本身無法保持穩定形狀的肽中(例如胰島素)。 |
天冬氨酸 |
D | Asp | 行為類似於穀氨酸。帶有一個帶強負電荷的親水性酸性基團。通常位於蛋白質的外表面,使其可溶於水。與帶正電荷的分子和離子結合,常用於酶中固定金屬離子。當位於蛋白質內部時,天冬氨酸和穀氨酸通常與精氨酸和賴氨酸配對。 |
穀氨酸 |
E | Glu | 行為類似於天冬氨酸。具有更長、更靈活的側鏈。 |
苯丙氨酸 |
F | Phe | 對人類至關重要。苯丙氨酸、酪氨酸和色氨酸在側鏈上含有大的剛性芳香基團。這些是最大的氨基酸。與異亮氨酸、亮氨酸和纈氨酸一樣,它們是疏水的,並且傾向於朝向摺疊的蛋白質分子的內部定向。苯丙氨酸可以轉化為酪氨酸。 |
甘氨酸 |
G | Gly | 由於α碳上的兩個氫原子,甘氨酸沒有旋光性。它是最小的氨基酸,易於旋轉,為蛋白質鏈添加了靈活性。它能夠適應最緊密的間隙,例如膠原蛋白的三螺旋。由於過多的靈活性通常不可取,因此作為結構組分,它不如丙氨酸常見。 |
組氨酸 |
H | His | 即使在弱酸性條件下,氮的質子化也會發生,改變組氨酸和整個多肽的性質。它被許多蛋白質用作調節機制,在酸性區域(例如晚期內體或溶酶體)中改變多肽的構象和行為,強制酶發生構象變化。然而,這隻需要很少的組氨酸,因此它相對稀少。 |
異亮氨酸 |
I | Ile | 對人類至關重要。異亮氨酸、亮氨酸和纈氨酸具有大的脂肪族疏水側鏈。它們的分子是剛性的,它們的相互疏水相互作用對於蛋白質的正確摺疊至關重要,因為這些鏈往往位於蛋白質分子的內部。 |
| 亮氨酸或異亮氨酸 | J | Xle | 當任一氨基酸可能佔據一個位置時的佔位符 |
賴氨酸 |
K | Lys | 對人類至關重要。行為類似於精氨酸。包含一個長而靈活的側鏈,其末端帶正電荷。鏈的靈活性使得賴氨酸和精氨酸適合與表面上具有多個負電荷的分子結合。例如,DNA結合蛋白的活性區域富含精氨酸和賴氨酸。強電荷使得這兩種氨基酸容易位於蛋白質的外部親水錶面;當它們位於內部時,它們通常與相應的帶負電荷的氨基酸配對,例如天冬氨酸或穀氨酸。 |
亮氨酸 |
L | Leu | 對人類至關重要。行為類似於異亮氨酸和纈氨酸。參見異亮氨酸。 |
蛋氨酸 |
M | Met | 對人類至關重要。始終是第一個被整合到蛋白質中的氨基酸;有時在翻譯後被移除。與半胱氨酸一樣,含有硫,但帶有甲基而不是氫。該甲基可以被啟用,並用於許多反應中,在這些反應中,新的碳原子被新增到另一個分子中。 |
天冬醯胺 |
N | Asn | 類似於天冬氨酸。Asn 包含一個醯胺基團,而 Asp 具有一個羧基。 |
| 吡咯賴氨酸 | O | Pyl | 類似於賴氨酸,帶有吡咯烷環。 |
脯氨酸 |
P | Pro | 對 N 末端胺基含有不尋常的環,這迫使 CO-NH 醯胺序列處於固定構象。可以破壞蛋白質摺疊結構,例如α 螺旋或β 摺疊,迫使蛋白質鏈產生所需的彎曲。在膠原蛋白中很常見,在那裡它經常發生翻譯後修飾形成羥脯氨酸。 |
谷氨醯胺 |
Q | Gln | 類似於穀氨酸。Gln 包含一個醯胺基團,而 Glu 具有一個羧基。用於蛋白質中,並作為氨的儲存。體內最豐富的氨基酸。 |
精氨酸 |
R | Arg | 在功能上類似於賴氨酸。 |
絲氨酸 |
S | Ser | 絲氨酸和蘇氨酸有一個短的基團,其末端是羥基基團。它的氫很容易被移除,因此絲氨酸和蘇氨酸經常在酶中充當氫供體。兩者都非常親水,因此可溶性蛋白質的外區域往往富含它們。 |
蘇氨酸 |
T | Thr | 對人類至關重要。行為類似於絲氨酸。 |
| 硒代半胱氨酸 | U | Sec | 硒化形式的半胱氨酸,它取代了硫。 |
纈氨酸 |
V | Val | 對人類至關重要。行為類似於異亮氨酸和亮氨酸。參見異亮氨酸。 |
色氨酸 |
W | Trp | 對人類至關重要。行為類似於苯丙氨酸和酪氨酸(參見苯丙氨酸)。血清素的前體。天然熒光。 |
| 未知 | X | Xaa | 當氨基酸未知或不重要時的佔位符。 |
酪氨酸 |
Y | Tyr | 行為類似於苯丙氨酸(酪氨酸的前體)和色氨酸(參見苯丙氨酸)。黑色素、腎上腺素和甲狀腺激素的前體。天然熒光,儘管熒光通常會被能量轉移到色氨酸而猝滅。 |
| 穀氨酸或谷氨醯胺 | Z | Glx | 當兩種氨基酸都可能佔據一個位置時的佔位符。 |
-
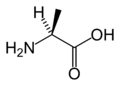 L-丙氨酸
L-丙氨酸
(Ala / A) -
 L-精氨酸
L-精氨酸
(Arg / R) -
 L-天冬醯胺
L-天冬醯胺
(Asn / N) -
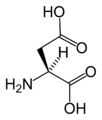 L-天冬氨酸
L-天冬氨酸
(Asp / D) -
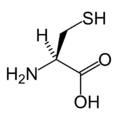 L-半胱氨酸
L-半胱氨酸
(Cys / C) -
 L-穀氨酸
L-穀氨酸
(Glu / E) -
 L-谷氨醯胺
L-谷氨醯胺
(Gln / Q) -
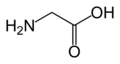 甘氨酸
甘氨酸
(Gly / G) -
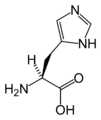 L-組氨酸
L-組氨酸
(His / H) -
 L-異亮氨酸
L-異亮氨酸
(Ile / I) -
 L-亮氨酸
L-亮氨酸
(Leu / L) -
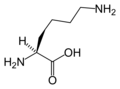 L-賴氨酸
L-賴氨酸
(Lys / K) -
 L-蛋氨酸
L-蛋氨酸
(Met / M) -
 L-苯丙氨酸
L-苯丙氨酸
(Phe / F) -
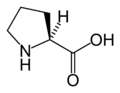 L-脯氨酸
L-脯氨酸
(Pro / P) -
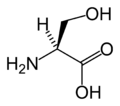 L-絲氨酸
L-絲氨酸
(Ser / S) -
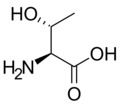 L-蘇氨酸
L-蘇氨酸
(Thr / T) -
 L-色氨酸
L-色氨酸
(Trp / W) -
 L-酪氨酸
L-酪氨酸
(Tyr / Y) -
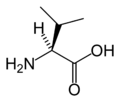 L-纈氨酸
L-纈氨酸
(Val / V) -
 L-硒代半胱氨酸
L-硒代半胱氨酸
(Sec / U) -
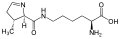 L-吡咯賴氨酸
L-吡咯賴氨酸
(Pyl / O)

.png)



















氨基酸分類
[edit | edit source]由遺傳密碼直接編碼的 20 種氨基酸可以根據它們的性質分為幾組。重要的因素包括電荷、親水性或疏水性、大小和官能團。氨基酸通常根據其側鏈的性質分為四組。側鏈可以使氨基酸成為弱酸或弱鹼,以及如果側鏈是極性的親水性物質,或者如果側鏈是非極性的疏水性物質。

蛋白質氨基酸透過縮合反應組合成單個多肽鏈。這種反應是由催化的核糖體在稱為翻譯的過程中進行的。
| 必需 | 非必需 |
|---|---|
| 異亮氨酸 | 丙氨酸 |
| 亮氨酸 | 天冬醯胺 |
| 賴氨酸 | 天冬氨酸 |
| 蛋氨酸 | 半胱氨酸* |
| 苯丙氨酸 | 穀氨酸 |
| 蘇氨酸 | 谷氨醯胺* |
| 色氨酸 | 甘氨酸* |
| 纈氨酸 | 脯氨酸* |
| 硒代半胱氨酸* | |
| 絲氨酸* | |
| 酪氨酸* | |
| 精氨酸* | |
| 組氨酸* | |
| 鳥氨酸* | |
| 牛磺酸* |
極性和非極性氨基酸及其單字母和三字母程式碼
| 氨基酸 | 三字母程式碼 | 單字母程式碼 | 側鏈極性 | 側鏈電荷 (pH 7.4) | 疏水性指數 | 吸光度 λmax(nm) | ε 在 λmax (x10−3 M−1 cm−1) |
|---|---|---|---|---|---|---|---|
| 丙氨酸 | Ala | A | 非極性 | 中性 | 1.8 | ||
| 精氨酸 | Arg | R | 極性 | 正 | −4.5 | ||
| 天冬醯胺 | Asn | N | 極性 | 中性 | −3.5 | ||
| 天冬氨酸 | Asp | D | 極性 | 負 | −3.5 | ||
| 半胱氨酸 | Cys | C | 非極性 | 中性 | 2.5 | 250 | 0.3 |
| 穀氨酸 | Glu | E | 極性 | 負 | −3.5 | ||
| 谷氨醯胺 | Gln | Q | 極性 | 中性 | −3.5 | ||
| 甘氨酸 | Gly | G | 非極性 | 中性 | −0.4 | ||
| 組氨酸 | His | H | 極性 | 正(10%) 中性(90%) |
−3.2 | 211 | 5.9 |
| 異亮氨酸 | Ile | I | 非極性 | 中性 | 4.5 | ||
| 亮氨酸 | Leu | L | 非極性 | 中性 | 3.8 | ||
| 賴氨酸 | Lys | K | 極性 | 正 | −3.9 | ||
| 蛋氨酸 | Met | M | 非極性 | 中性 | 1.9 | ||
| 苯丙氨酸 | Phe | F | 非極性 | 中性 | 2.8 | 257, 206, 188 | 0.2, 9.3, 60.0 |
| 脯氨酸 | Pro | P | 非極性 | 中性 | −1.6 | ||
| 絲氨酸 | Ser | S | 極性 | 中性 | −0.8 | ||
| 蘇氨酸 | Thr | T | 極性 | 中性 | −0.7 | ||
| 色氨酸 | Trp | W | 非極性 | 中性 | −0.9 | 280, 219 | 5.6, 47.0 |
| 酪氨酸 | Tyr | Y | 極性 | 中性 | −1.3 | 274, 222, 193 | 1.4, 8.0, 48.0 |
| 纈氨酸 | Val | V | 非極性 | 中性 | 4.2 |
此外,還有兩種額外的氨基酸透過覆蓋終止密碼子來整合
| 第 21 和 22 個氨基酸 | 3 字母 | 1 字母 |
|---|---|---|
| 硒代半胱氨酸 | Sec | U |
| 吡咯賴氨酸 | Pyl | O |
除了特定的氨基酸程式碼外,當化學或晶體學分析無法確定肽或蛋白質中殘基的身份時,會使用佔位符。
| 模稜兩可的氨基酸 | 3 字母 | 1 字母 |
|---|---|---|
| 天冬醯胺或天冬氨酸 | Asx | B |
| 谷氨醯胺或穀氨酸 | Glx | Z |
| 亮氨酸或異亮氨酸 | Xle | J |
| 未指定或未知的氨基酸 | Xaa | X |
Unk有時用作Xaa的替代,但不如Xaa標準。
此外,許多非標準氨基酸有特定的程式碼。例如,一些肽類藥物,如硼替佐米或MG132是人工合成的,並保留其保護基團,這些基團有特定的程式碼。硼替佐米是Pyz-Phe-boroLeu,而MG132是Z-Leu-Leu-Leu-al。此外,為了幫助分析蛋白質結構,光交聯氨基酸類似物也可用。這些包括光亮氨酸 (pLeu) 和光甲硫氨酸 (pMet)。[5]
肽鍵
[edit | edit source]
肽鍵(醯胺鍵)是兩個分子之間形成的共價化學鍵,當一個分子的羧基與另一個分子的氨基反應時形成,釋放一個水分子 (H2O)。這是一個脫水合成反應(也稱為縮合反應),通常發生在氨基酸之間。形成的 C(O)NH 鍵稱為肽鍵,形成的分子為醯胺。四原子官能團 -C(=O)NH- 稱為肽鍵。多肽和蛋白質是透過肽鍵連線在一起的氨基酸鏈,就像 PNA 的主鏈一樣。
肽鍵可以透過醯胺水解(加水)斷裂。蛋白質中的肽鍵是亞穩的,這意味著在水存在的情況下,它們會自發斷裂,釋放 2-4 kcal/mol 的自由能,但這個過程非常緩慢。在生物體中,這個過程是由酶加速的。生物體也利用酶形成肽鍵;這個過程需要自由能。肽鍵的吸收波長為 190-230 nm。
由於雙鍵電子的離域,肽鍵傾向於平面。剛性的肽二面角 ω(C1 和 N 之間的鍵)始終接近 180 度。二面角 phi φ(N 和 Cα 之間的鍵)和 psi ψ(Cα 和 C1 之間的鍵)可以具有一定的可能值範圍。這些角度是蛋白質的內部自由度,它們控制著蛋白質的構象。它們受幾何形狀限制,限制在特定二級結構元素的允許範圍內,並在拉馬錢德蘭圖中表示。下表給出了一些重要的鍵長。[6]
| 肽鍵 | 平均長度 | 單鍵 | 平均長度 | 氫鍵 | 平均值(±30) |
| Ca -C | 153 pm | C - C | 154 pm | O-H --- O-H | 280 pm |
| C - N | 133 pm | C - N | 148 pm | N-H --- O=C | 290 pm |
| N - Ca | 146 pm | C - O | 143 pm | O-H --- O=C | 280 pm |
β-肽
[edit | edit source]在 α 氨基酸(左側的分子)中,羧酸基團(紅色)和氨基基團(藍色)都連線到同一個碳中心,稱為 α 碳 (),因為它距離羧酸基團一個原子。在 β 氨基酸中,氨基連線到 β 碳 (),它存在於 20 種標準氨基酸中的大多數。只有甘氨酸沒有 β 碳,這意味著 β-甘氨酸是不可能的。


β 氨基酸的化學合成可能具有挑戰性,特別是考慮到連線到 β 碳的官能團的多樣性以及維持手性的必要性。在所示的丙氨酸分子中,β 碳是非手性的;然而,大多數較大的氨基酸都有手性 原子。已經引入了許多合成機制來有效地形成 β 氨基酸及其衍生物[7][8],特別是那些基於阿恩特-艾斯特合成的。
存在兩種主要的 β-肽型別:有機殘基 (R) 靠近胺的稱為 β3-肽,而位置靠近羰基的稱為 β2-肽。[9]
酶
[edit | edit source]酶通常是球狀蛋白質,大小從 4-草醯巴豆酸互變異構酶單體的 62 個氨基酸殘基到動物脂肪酸合酶的 2500 多個殘基不等。少數基於 RNA 的生物催化劑存在,最常見的是核糖體;這些被稱為 RNA 酶或核酶。酶的活性由其三維結構決定。然而,儘管結構決定功能,但僅僅從結構預測一種新的酶的活性是一個非常困難的問題,目前還沒有解決。
大多數酶比它們作用的底物大得多,只有酶的一小部分(大約 3-4 個氨基酸)直接參與催化。包含這些催化殘基、結合底物並進行反應的區域被稱為活性位點。酶也可以包含結合輔因子的位點,輔因子對於催化是必需的。一些酶還具有結合小分子的結合位點,這些小分子通常是催化反應的直接或間接產物或底物。這種結合可以提高或降低酶的活性,提供了一種反饋調節的手段。與所有蛋白質一樣,酶是摺疊成三維產物的長線性氨基酸鏈。每個獨特的氨基酸序列都會產生特定的結構,該結構具有獨特的性質。單個蛋白質鏈有時可以聚整合一起形成蛋白質複合物。大多數酶可以被熱或化學變性劑變性,即展開和失活,這會破壞蛋白質的三維結構。根據酶的不同,變性可能是可逆的或不可逆的。使用時間分辨晶體學方法可以獲得酶與底物或底物類似物在反應過程中形成的複合物的結構。[10]
酶的分類
[edit | edit source]酶的名稱通常源於其底物或其催化的化學反應,其詞尾為 -ase。例如乳糖酶、醇脫氫酶和 DNA 聚合酶。這可能導致具有相同功能的不同酶,稱為同工酶,具有相同的名稱。同工酶具有不同的氨基酸序列,可以透過其最佳 pH 值、動力學性質或免疫學來區分。同工酶和同工酶是同源蛋白。此外,酶催化的正常生理反應可能與人工條件下不同。這可能導致同一酶被賦予兩個不同的名稱。例如,工業上用於將葡萄糖轉化為甜味劑果糖的葡萄糖異構酶,在體內是木糖異構酶。
國際生物化學與分子生物學聯盟制定了酶的命名法,即 EC 編號。酶委員會編號 (EC 編號) 是基於酶催化的化學反應對酶進行的數值分類方案。作為酶命名的系統,每個 EC 編號都與相應酶的推薦名稱相關聯。每種酶都由一個以“EC”開頭的四位數序列來描述。第一個數字根據其機制將酶廣泛分類。嚴格地說,EC 編號不指定酶,而是指定酶催化的反應。如果不同的酶(例如來自不同生物體的酶)催化相同的反應,那麼它們將獲得相同的 EC 編號。相比之下,UniProt 識別符號透過其氨基酸序列唯一地指定蛋白質。[11]
EC 1 氧化還原酶:催化氧化/還原反應
EC 2 轉移酶:轉移一個官能團(例如甲基或磷酸基團)
EC 3 水解酶:催化各種鍵的水解
EC 4 裂解酶:透過除水解和氧化以外的其他方式斷裂各種鍵
EC 5 異構酶:催化單個分子內的異構化變化
EC 6 連線酶:透過共價鍵連線兩個分子。
| 組 | 催化的反應 | 典型的反應 | 具有俗名的酶示例 |
|---|---|---|---|
| EC 1 氧化還原酶 |
催化氧化/還原反應;將 H 和 O 原子或電子從一種物質轉移到另一種物質 | AH + B → A + BH (還原) A + O → AO (氧化) |
脫氫酶,氧化酶 |
| EC 2 轉移酶 |
將一個官能團從一種物質轉移到另一種物質。該基團可以是甲基、醯基、氨基或磷酸基團 | AB + C → A + BC | 轉氨酶,激酶 |
| EC 3 水解酶 |
透過水解從底物形成兩種產物 | AB + H2O → AOH + BH | 脂肪酶,澱粉酶,肽酶 |
| EC 4 裂解酶 |
底物非水解新增或去除基團。C-C、C-N、C-O 或 C-S 鍵可能會斷裂 | RCOCOOH → RCOH + CO2 或 [x-A-B-Y] → [A=B + X-Y] | 脫羧酶 |
| EC 5 異構酶 |
分子內重排,即單個分子內的異構化變化 | AB → BA | 異構酶,變位酶 |
| EC 6 連線酶 |
透過合成新的 C-O、C-S、C-N 或 C-C鍵將兩個分子連線在一起,同時分解ATP | X + Y+ ATP → XY + ADP + Pi | 合成酶 |
氧化還原酶
[edit | edit source]在分子生物學和生物化學中,氧化還原酶是一種催化電子從一個分子(還原劑,也稱為氫或電子供體)轉移到另一個分子(氧化劑,也稱為氫或電子受體)的酶。這組酶通常利用 NADP 或 NAD 作為輔因子。一般來說,多肽是無支鏈的聚合物,因此它們的初級結構通常可以透過沿其主鏈的氨基酸序列來指定。然而,蛋白質可以發生交聯,最常見的是透過二硫鍵,並且初級結構還需要指定交聯原子,例如,指定蛋白質中參與二硫鍵的半胱氨酸。其他交聯包括脫氫脯氨酸……多肽鏈的手性中心可能會發生外消旋化。特別是,蛋白質中通常發現的 L-氨基酸可以在 Cα 原子上自發異構化形成 D-氨基酸,D-氨基酸不能被大多數蛋白酶裂解。[13]
蛋白質的結構
[edit | edit source]
蛋白質的初級結構
[edit | edit source]
蛋白質是 α-氨基酸的線性鏈的提議幾乎同時由兩位科學家在 1902 年的同一會議上提出,即第 74 屆德國科學家和醫師學會會議,在卡爾斯巴德舉行。弗朗茨·霍夫邁斯特在上午提出了這個提議,基於他對蛋白質中雙縮脲反應的觀察。幾個小時後,霍夫邁斯特被埃米爾·費歇爾接替,費歇爾積累了大量支援肽鍵模型的化學細節。為了完整起見,蛋白質含有醯胺鍵的提議早在 1882 年就由法國化學家E. Grimaux提出。[15]
儘管有這些資料以及後來的證據表明蛋白水解消化的蛋白質僅產生寡肽,但蛋白質是氨基酸的線性、無支鏈聚合物的觀點並沒有立即被接受。一些德高望重的科學家,如威廉·阿斯特伯裡,懷疑共價鍵是否足夠強以將如此長的分子結合在一起;他們擔心熱振動會將如此長的分子震碎。赫爾曼·施陶丁格在 1920 年代面臨著類似的偏見,當時他認為橡膠是由大分子組成的。因此,出現了幾個替代假設。膠體蛋白假說指出蛋白質是較小分子的膠體集合。這個假設在 1920 年代被特奧多爾·斯維德伯格的超速離心測量所駁斥,超速離心測量表明蛋白質具有明確的、可重複的分子量,以及阿恩·蒂塞利烏斯進行的電泳測量,表明蛋白質是單個分子。
第二個假設是環醇假說,由多蘿西·溫奇提出,該假說提出線性多肽經歷了一種化學環醇重排 C=O + HN C(OH)-N,其交聯了其主鏈醯胺基團,形成了二維織物。各種研究人員提出了蛋白質的其他初級結構,例如埃米爾·阿貝德哈爾登的二酮哌嗪模型和 1942 年特羅恩斯高德的吡咯/哌啶模型。儘管從未得到太多重視,但當弗雷德里克·桑格成功地對胰島素進行測序以及麥克斯·佩魯茨和約翰·肯德魯透過晶體學測定肌紅蛋白和血紅蛋白時,這些替代模型最終被否定了。
肽和蛋白質的初級結構是指其氨基酸結構單元的線性序列。“初級結構”一詞最初由林德斯特羅姆-朗在 1951 年提出。按照慣例,蛋白質的初級結構從氨基末端 (N) 端到羧基末端 (C) 端報告。蛋白質的翻譯後修飾,如二硫鍵形成、磷酸化和糖基化,通常也被認為是初級結構的一部分,無法從基因中讀取。
蛋白質的二級結構
[edit | edit source]
二級結構是指高度規則的區域性亞結構。兩種主要的二級結構,α螺旋 和 β摺疊,是由萊納斯·鮑林及其同事在 1951 年提出的。[16] 這些二級結構由主鏈肽基團之間的氫鍵模式定義。它們具有規則的幾何形狀,被限制在拉氏圖上的二面角 ψ 和 φ 的特定值。α 螺旋和 β 摺疊都代表了一種使肽骨架中所有氫鍵供體和受體飽和的方式。蛋白質中的一些部分是有序的,但沒有形成任何規則的結構。它們不應該與無規捲曲混淆,無規捲曲是指缺乏任何固定三維結構的未摺疊多肽鏈。幾個連續的二級結構可以形成一個 "超二級結構單元"。[17]

氨基酸在形成各種二級結構元素的能力上有所不同。脯氨酸和甘氨酸有時被稱為“螺旋破壞者”,因為它們會破壞 α 螺旋主鏈構象的規律性;然而,它們兩者都具有不同尋常的構象能力,並且通常存在於轉角中。傾向於在蛋白質中採用螺旋構象的氨基酸包括蛋氨酸、丙氨酸、亮氨酸、穀氨酸和賴氨酸(在氨基酸單字母程式碼中為“MALEK”);相反,大的芳香族殘基(色氨酸、酪氨酸和苯丙氨酸)和 Cβ 支鏈氨基酸(異亮氨酸、纈氨酸和蘇氨酸)傾向於採用 β 摺疊構象。然而,這些偏好不足以產生一種可靠的方法,僅從序列中預測二級結構。蛋白質中的二級結構由氫鍵介導的區域性殘基間相互作用組成,或不組成。最常見的二級結構是 α 螺旋和 β 摺疊。其他螺旋,如 310 螺旋和 π 螺旋,被計算出具有能量上有利的氫鍵模式,但在天然蛋白質中很少觀察到,除非在 α 螺旋的末端,因為螺旋中心的骨架堆積不利。
拉氏圖(也稱為拉氏圖或拉氏圖或 [φ,ψ] 圖),由 Gopalasamudram Narayana Ramachandran 和 Viswanathan Sasisekharan 開發,是一種視覺化蛋白質結構中氨基酸殘基的二面角 ψ 相對於 φ 的方法。[18] 它顯示了多肽的 ψ 和 φ 角的可能構象。
在數學上,拉氏圖是函式 的視覺化。該函式的定義域是環面。因此,傳統的拉氏圖是環面在平面上的投影,導致失真檢視和不連續性的出現。可以預期,較大的側鏈會導致更多的限制,因此拉氏圖中允許的區域更小。在實踐中,情況似乎並非如此;只有 α 位置的亞甲基基團有影響。甘氨酸在 α 位置有一個氫原子,其範德華半徑小於甲基基團。因此,它的限制最少,這在甘氨酸的拉氏圖中很明顯,對於甘氨酸,允許的區域要大得多。相反,脯氨酸的拉氏圖僅顯示了 ψ 和 φ 的非常有限的可能組合。拉氏圖是在第一個原子解析度的蛋白質結構確定之前計算出來的。40 年後,透過 X 射線晶體學確定了數萬個高解析度蛋白質結構,並沉積到蛋白質資料庫 (PDB) 中。從 1000 個不同的蛋白質鏈中,繪製了超過 200 000 個氨基酸的拉氏圖,顯示了一些顯著的差異,特別是對於甘氨酸(Hovmöller 等人,2002)。發現左上角區域被分成兩部分;一個在左邊包含 β 摺疊中的氨基酸,另一個在右邊包含這種構象的無規捲曲中的氨基酸。也可以用這種方式繪製多糖和其他聚合物的二面角。對於前兩個蛋白質側鏈二面角,類似的圖是 Janin 圖。

α 螺旋
α 螺旋中的氨基酸排列成右手螺旋結構,其中每個氨基酸殘基對應於螺旋的 100° 轉彎(即螺旋每轉 3.6 個殘基),以及沿螺旋軸的 1.5 Å(0.15 nm)平移。(短段左手螺旋有時會出現在大量非手性甘氨酸氨基酸中,但對其他正常的生物 L-氨基酸來說是不利的。)α 螺旋的螺距(螺旋的一個連續轉彎之間的垂直距離)為 5.4 Å(0.54 nm),它是 1.5 和 3.6 的乘積。最重要的是,一個氨基酸的 N-H 基團與前面四個殘基的 C=O 基團形成氫鍵;這種重複的氫鍵是 α 螺旋最突出的特徵。官方國際命名法指定了兩種定義 α 螺旋的方法,規則 6.2 是根據重複的 φ、ψ 扭轉角,規則 6.3 是根據螺距和氫鍵的組合模式。不同的氨基酸序列具有形成 α 螺旋結構的不同傾向。蛋氨酸、丙氨酸、亮氨酸、未帶電荷的穀氨酸和賴氨酸(在氨基酸單字母程式碼中為“MALEK”)都具有特別高的螺旋形成傾向,而脯氨酸和甘氨酸則具有較差的螺旋形成傾向。脯氨酸要麼破壞螺旋,要麼使螺旋彎曲,這兩種情況都是因為脯氨酸不能捐贈醯胺氫鍵(因為沒有醯胺氫),而且它的側鏈會與前一個螺旋的骨架發生空間位阻。在一個螺旋中,這會導致螺旋軸彎曲約 30°。[19] 然而,脯氨酸通常被視為螺旋的第一個殘基,這可能是由於其結構剛性。在另一個極端,甘氨酸也往往會破壞螺旋,因為它很高的構象靈活性使其在熵上採用相對受限的 α 螺旋結構很昂貴。


β 摺疊 第一個 β 摺疊結構是由威廉·阿斯特伯裡在 1930 年代提出的。他提出了平行或反平行延伸 β 摺疊之間形成氫鍵的想法。然而,阿斯特伯裡沒有關於氨基酸鍵幾何形狀的必要資料來構建準確的模型,特別是他當時不知道肽鍵是平面的。萊納斯·鮑林和羅伯特·科裡在 1951 年提出了一個改進的版本。
β 摺疊(也稱為 β 摺疊片)是蛋白質中第二種規則的二級結構,只是比 α 螺旋略不常見。β 摺疊由至少兩個或三個主鏈氫鍵橫向連線的 β 摺疊組成,形成一個通常扭曲的、褶皺的片。β 摺疊(也稱為 β 摺疊)是多肽鏈的一段,通常長 3 到 10 個氨基酸,主鏈處於幾乎完全伸展的構象中。
涉及 β 摺疊的非常簡單的結構模體 是β 摺疊髮夾,其中兩個反平行摺疊透過一個 2 到 5 個殘基的短環連線起來,其中一個通常是甘氨酸或脯氨酸,它們兩者都可以假設緊湊轉角所需的非尋常二面角構象。然而,單個摺疊也可以以更復雜的方式連線起來,形成長環,這些長環可能包含α 螺旋,甚至整個蛋白質結構域。
希臘鍵模體 希臘鍵模體由四個相鄰的反平行摺疊及其連線環組成。它由三個由髮夾連線的反平行摺疊組成,而第四個摺疊與第一個摺疊相鄰,並透過更長的環連線到第三個摺疊。這種型別的結構在蛋白質摺疊過程中很容易形成。[20][21] 它以希臘裝飾藝術中常見的圖案命名(見回紋)。
β-α-β 基序 由於其組成氨基酸的手性,所有鏈在大多數高階 β 摺疊結構中都表現出“右手”扭曲。特別是,兩個平行鏈之間的連線環幾乎總是具有右手交叉手性,這受到片材固有扭曲的強烈偏愛。此連線環通常包含一個螺旋區域,在這種情況下,它被稱為 β-α-β 基序。一個密切相關的基序被稱為 β-α-β-α 基序,它構成了最常見觀察到的蛋白質 三級結構,即 TIM 桶 的基本組成部分。
β-彎曲基序 一個簡單的 超二級 蛋白質拓撲結構,由 2 個或多個連續的反平行 β 鏈組成,透過 髮夾 環連線在一起。 [22] [23] 此基序在 β 摺疊中很常見,可以在幾種結構體系中找到,包括 β 桶 和 β 推進器。

Psi 環基序 Psi 環,Ψ 環,基序由兩個反平行鏈組成,一個鏈介於兩者之間,透過氫鍵連線到兩者。 [24] 如 Hutchinson 等人 (1990) 所述,單一 Ψ 環有四種可能的鏈拓撲結構。此基序很少見,因為導致其形成的過程似乎不太可能在蛋白質摺疊過程中發生。Ψ 環首先在 天冬氨酸蛋白酶 家族中被發現。 [25]
捲曲螺旋
Francis Crick 在 1952 年提出了 α 角蛋白卷曲螺旋的可能性,以及確定其結構的數學方法。值得注意的是,這緊隨 1951 年 Linus Pauling 及其同事提出的 α 螺旋結構。
捲曲螺旋通常包含一個重複的模式,hxxhcxc,疏水性 (h) 和帶電荷 (c) 氨基酸殘基,被稱為七肽重複。七肽重複中的位置通常標記為 abcdefg,其中 a 和 d 是疏水位置,通常被異亮氨酸、亮氨酸或纈氨酸佔據。將具有此重複模式的序列摺疊成 α 螺旋二級結構會導致疏水殘基呈“條紋”狀,以左手方式繞螺旋輕輕盤繞,形成兩親結構。在細胞質充滿水的環境中,兩種這種螺旋排列的最有利方式是將疏水鏈包裹在一起,夾在親水氨基酸之間。因此,疏水錶面的埋藏提供了寡聚化的熱力學驅動力。捲曲螺旋介面中的堆積非常緊密,在 a 和 d 殘基的側鏈之間幾乎完全存在範德華接觸。這種緊密的堆積最初是由 **弗朗西斯·克里克在 1952 年預測**的,被稱為“突起進入孔洞”堆積。α 螺旋可以是平行的或反平行的,並且通常採用左手超螺旋。儘管不受青睞,但一些右手卷曲螺旋也在自然界和設計的蛋白質中被觀察到。 [26]
| 幾何屬性 | α-螺旋 | 310 螺旋 | π-螺旋 |
|---|---|---|---|
| 每圈殘基數 | 3.6 | 3.0 | 4.4 |
| 每殘基平移 | 1.5Å | 2.0Å | 1.1Å |
| 螺旋半徑 | 2.3Å | 1.9Å | 2.8Å |
| 螺距 | 5.4Å | 6.0Å | 4.8Å |

蛋白質的三級結構
[edit | edit source]三級結構被認為很大程度上由蛋白質的一級結構決定——它所組成的氨基酸序列。從一級結構預測三級結構的努力通常被稱為蛋白質結構預測。然而,蛋白質合成和允許摺疊的環境是其最終形狀的重要決定因素,通常不會被當前的預測方法直接考慮。
在球狀蛋白質中,三級相互作用經常透過疏水氨基酸殘基在蛋白質核心中的隔離而穩定,從該核心排除水,並因此在蛋白質的水暴露表面富集帶電荷或親水殘基。在沒有在細胞質中停留的分泌蛋白中,半胱氨酸殘基之間的二硫鍵有助於維持蛋白質的三級結構。許多在功能和進化上無關的蛋白質中出現各種常見且穩定的三級結構——例如,許多蛋白質的形狀像 TIM 桶,以酶磷酸三糖異構酶命名。另一種常見結構是高度穩定的二聚體捲曲螺旋結構,由 2-7 個 α 螺旋組成。
迄今為止已知的蛋白質結構大多數是用 X 射線晶體學實驗技術解決的,該技術通常提供高解析度資料,但沒有提供關於蛋白質構象靈活性的時間依賴性資訊。解決蛋白質結構的第二種常見方法是使用核磁共振,該方法通常提供較低解析度的資料,並且僅限於相對較小的蛋白質,但可以提供關於蛋白質在溶液中運動的時間依賴性資訊。雙偏振干涉法是一種時間分辨分析方法,用於確定表面捕獲蛋白質的整體構象和構象變化,為這些高解析度方法提供補充資訊。關於可溶性球狀蛋白質的三級結構特徵比關於膜蛋白的瞭解更多,因為後者類別使用這些方法極其難以研究。 [28]
蛋白質的四級結構
[edit | edit source]一些蛋白質實際上是多個 **多肽鏈** 的集合,在更大集合的背景下被稱為蛋白質亞基。除了亞基的三級結構之外,多亞基蛋白質還具有四級結構,即亞基組裝成的排列。由具有不同功能的亞基組成的酶有時被稱為全酶,其中一些部分被稱為調節亞基,而功能核心被稱為催化亞基。具有四級結構的蛋白質的例子包括血紅蛋白、DNA 聚合酶和離子通道。其他被稱為多蛋白複合物的集合也具有四級結構。例如 **核小體和微管**。
四級結構的變化可以透過單個亞基內的構象變化或亞基相對於彼此的重新定位來發生。正是透過這種變化,它構成“多聚”酶中的協同性和變構作用的基礎,許多蛋白質經歷調節並執行其生理功能。以上定義遵循生物化學的經典方法,該方法是在蛋白質和功能性蛋白質單元之間的區別難以闡明的時候建立的。最近,人們在討論蛋白質的四級結構時提到蛋白質-蛋白質相互作用,並將所有蛋白質的集合視為蛋白質複合物。 [29]
蛋白質結構測定
[edit | edit source]
蛋白質資料庫中大約 90% 的蛋白質結構是透過 X 射線晶體學確定的。這種方法使人們能夠測量蛋白質中電子的 3D 密度分佈(在晶體狀態下),從而推斷所有原子的 3D 座標,以便以一定解析度確定它們。大約 9% 的已知蛋白質結構是透過核磁共振技術獲得的。可以透過圓二色性或雙偏振干涉法確定二級結構組成。冷凍電子顯微鏡最近已成為一種以高解析度(小於 5 埃或 0.5 奈米)確定蛋白質結構的方法,預計在未來十年將成為高解析度工作工具的效力將會提高。對於使用非常大的蛋白質複合物(如病毒衣殼蛋白和澱粉樣蛋白纖維)進行研究的研究人員來說,這種技術仍然是一項寶貴的資源。
X 射線晶體學
[edit | edit source]生物分子的X射線晶體學隨著多蘿西·克勞福特·霍奇金的出現而蓬勃發展,她解開了膽固醇(1937年)、維生素B12(1945年)和青黴素(1954年)的結構,並因此於1964年獲得了諾貝爾化學獎。1969年,她成功地解開了胰島素的結構,為此她研究了30多年。[30]
X射線晶體學是一種確定晶體中原子排列的方法,其中一束X射線照射到晶體上,並衍射到許多特定方向。蛋白質的晶體結構(不規則且比膽固醇大數百倍)從1950年代後期開始被解開,首先是抹香鯨肌紅蛋白的結構,由馬克斯·佩魯茨和約翰·肯德魯爵士解開,他們因此於1962年獲得了諾貝爾化學獎。[31] 自那次成功以來,已確定了超過61840種蛋白質、核酸和其他生物分子的X射線晶體結構。[32] 相比之下,在分析結構方面,最接近的競爭方法是核磁共振(NMR)波譜法,它已經解析了8759種化學結構。[33] 此外,晶體學可以解決任意大小的分子結構,而溶液態NMR則侷限於相對較小的分子(小於70 kDa)。X射線晶體學現在被科學家們常規地用來確定藥物如何與蛋白質靶標相互作用,以及哪些改變可以改進藥物。[34] 然而,內在膜蛋白的結晶仍然具有挑戰性,因為它們需要去垢劑或其他方法才能在分離狀態下溶解,而這些去垢劑通常會干擾結晶。這種膜蛋白是基因組的重要組成部分,包括許多具有重要生理意義的蛋白質,例如離子通道和受體。[35][36]
核磁共振波譜法或NMR
[edit | edit source]蛋白質核磁共振波譜法(通常縮寫為蛋白質NMR)是結構生物學的一個領域,其中使用NMR波譜法來獲取有關蛋白質結構和動力學的的資訊。該領域由理查德·R·恩斯特和庫爾特·武特里希等人在內開創[1]。蛋白質NMR技術不斷地在學術界和生物技術行業中使用和改進。透過NMR波譜法進行結構測定通常包括以下幾個階段,每個階段都使用一組高度專業化的技術。樣品製備、共振分配、約束生成以及結構計算和驗證。
如何測序蛋白質?
[edit | edit source]蛋白質測序是一種確定蛋白質氨基酸序列的技術,以及蛋白質採用的構象,以及它與任何非肽分子複合的程度。發現生物體中蛋白質的結構和功能是理解細胞過程的重要工具,並使針對特定代謝途徑的藥物更容易發明。蛋白質測序的兩種主要直接方法是**質譜法**和**艾德曼降解反應**。如果已知編碼蛋白質的DNA或mRNA序列,也可以從該序列生成氨基酸序列。然而,還有許多其他反應可以用來獲得關於蛋白質序列的更多有限資訊,這些資訊可以用作上述測序方法的預備步驟,或用來克服其中特定方面的不足。[37]
艾德曼降解
[edit | edit source]
艾德曼降解是蛋白質測序中非常重要的反應,因為它可以確定蛋白質的有序氨基酸組成。自動艾德曼測序儀現在被廣泛使用,能夠對長度約為50個氨基酸的肽進行測序。透過艾德曼降解對蛋白質進行測序的反應方案如下 - 其中一些步驟將在後面詳細說明。用氧化劑如**甲酸**或還原劑如**2-巰基乙醇**破壞蛋白質中的任何二硫鍵。可能需要使用如碘乙酸的保護基團來防止鍵重新形成。如果存在多個蛋白複合物鏈,則分離並純化單個鏈。
確定每條鏈的氨基酸組成。
確定每條鏈的末端氨基酸。
將每條鏈斷裂成長度小於50個氨基酸的片段。
分離並純化片段。
確定每個片段的序列。
以不同的斷裂模式重複。
構建整個蛋白質的序列。
消化成肽片段 長度超過約50-70個氨基酸的肽不能透過艾德曼降解可靠地測序。因此,需要將長蛋白鏈分解成小的片段,然後可以單獨測序。消化是透過內肽酶(如胰蛋白酶或胃蛋白酶)或化學試劑(如氰化溴)進行的。不同的酶產生不同的斷裂模式,並且片段之間的重疊可以用來構建一個完整的序列。
苯異硫氰酸酯在弱鹼性條件下與未帶電的末端氨基反應,形成迴圈的苯硫代氨基甲醯衍生物。然後,在酸性條件下,末端氨基酸的這種衍生物被裂解為噻唑啉酮衍生物。噻唑啉酮氨基酸然後被選擇性地提取到有機溶劑中,並用酸處理以形成更穩定的苯硫代腙(PTH)-氨基酸衍生物,該衍生物可以使用色譜法或電泳法進行鑑定。然後可以重複此過程以鑑定下一個氨基酸。這項技術的一個主要缺點是,以這種方式測序的肽不能超過50到60個殘基(實際上,小於30個)。肽的長度受迴圈衍生化並非總是完成的限制。衍生化問題可以透過在進行反應之前將大肽裂解成小肽來解決。它能夠準確地測序高達30個氨基酸,現代機器能夠在每個氨基酸上達到99%以上的效率。艾德曼降解的一個優點是,它只需要10-100皮摩爾的肽進行測序。艾德曼降解反應已經自動化,以加快這一過程。[38][39]
N末端氨基酸分析
[edit | edit source]確定哪個氨基酸構成肽鏈的N端有兩個原因:有助於將單個肽片段的序列排列成完整的鏈,以及因為第一輪Edman降解通常會被雜質汙染,因此無法準確確定N端氨基酸。以下是N端氨基酸分析的通用方法:用能選擇性標記末端氨基酸的試劑與肽反應。水解蛋白質。透過色譜法和與標準品的比較確定氨基酸。有很多不同的試劑可用於標記末端氨基酸。它們都與胺基反應,因此也會與賴氨酸等氨基酸側鏈中的胺基結合 - 因此,在解釋色譜圖時必須小心,以確保選擇了正確的點。兩種比較常用的試劑是桑格試劑(1-氟-2,4-二硝基苯)和丹磺醯衍生物,如丹磺醯氯。用於Edman降解的試劑苯異硫氰酸酯也可以使用。這裡與氨基酸組成測定中提出的問題相同,唯一的例外是無需染色,因為試劑會產生有色衍生物,並且只需要定性分析,因此氨基酸無需從色譜柱中洗脫,只需與標準品進行比較即可。另一個需要考慮的因素是,由於任何胺基都會與標記試劑反應,因此不能使用離子交換色譜,而應使用薄層色譜或高效液相色譜。 [40]
C端氨基酸分析
[edit | edit source]用於C端氨基酸分析的方法數量遠遠少於可用於N端分析的方法數量。最常用的方法是在蛋白質溶液中新增羧肽酶,定期取樣,並透過分析氨基酸濃度隨時間的變化圖來確定末端氨基酸。
質譜法
[edit | edit source]當今的研究人員正在使用質譜法作為表徵蛋白質的重要工具。蛋白質質譜法是指將質譜法應用於蛋白質的研究。兩種主要的完整蛋白質電離方法是電噴霧電離(ESI)和基質輔助雷射解吸/電離(MALDI)。為了符合現有質譜儀的效能和質量範圍,使用兩種方法來表徵蛋白質。首先,透過上述兩種技術之一電離完整的蛋白質,然後將其匯入質量分析儀。這種方法被稱為蛋白質分析的“自上而下”策略。其次,使用胰蛋白酶等蛋白酶將蛋白質酶解成更小的肽段。隨後,這些肽段被匯入質譜儀,並透過肽質量指紋圖譜或串聯質譜法進行鑑定。因此,這種後一種方法(也稱為“自下而上”蛋白質組學)使用肽水平上的鑑定來推斷蛋白質的存在。
完整蛋白質質量分析主要使用飛行時間(TOF)質譜儀或傅立葉變換離子迴旋共振(FT-ICR)。這兩種型別的儀器在這裡更受歡迎,因為它們具有較寬的質量範圍,並且在FT-ICR的情況下,具有較高的質量精度。蛋白水解肽的質量分析是一種更流行的蛋白質表徵方法,因為可以更便宜的儀器設計用於表徵。此外,一旦完整蛋白質被消化成更小的肽片段,樣品製備就變得更容易。用於肽質量分析最廣泛使用的儀器是MALDI飛行時間儀器,因為它們允許快速獲取肽質量指紋圖譜(PMF)(大約10秒內可以分析一個PMF)。多級四極杆飛行時間和四極杆離子阱也在這項應用中得到應用。
蛋白質型別
[edit | edit source]結合蛋白
[edit | edit source]結合蛋白是指與透過共價鍵或弱相互作用連線的其他化學基團相互作用的蛋白質。許多蛋白質只包含氨基酸,沒有其他化學基團,被稱為簡單蛋白質。然而,其他型別的蛋白質在水解時,除了氨基酸外,還會產生其他化學成分,這些蛋白質被稱為結合蛋白。結合蛋白的非氨基部分通常被稱為其輔基。大多數輔基是由維生素形成的。結合蛋白根據其輔基的化學性質進行分類。一些結合蛋白的例子是
脂蛋白
[edit | edit source]脂蛋白是包含蛋白質和脂質的生化組合體,脂質與蛋白質結合在一起。許多酶、轉運蛋白、結構蛋白、抗原、粘附素和毒素都是脂蛋白。例如,高密度 (HDL) 和低密度 (LDL) 脂蛋白能夠將脂肪帶到血液中,線粒體和葉綠體的跨膜蛋白以及細菌脂蛋白。
糖蛋白
[edit | edit source]糖蛋白是包含寡糖鏈(糖基)的蛋白質,寡糖鏈透過共價鍵連線到多肽側鏈。碳水化合物在蛋白質的共翻譯或翻譯後修飾中連線到蛋白質。這個過程被稱為糖基化。在具有胞外延伸段的蛋白質中,胞外延伸段通常被糖基化。糖蛋白通常是重要的整合膜蛋白,在細胞間相互作用中發揮作用。糖蛋白也存在於胞質溶膠中,但它們的功能以及在這種隔室中產生這些修飾的途徑尚未完全瞭解。糖蛋白通常是結合蛋白中最大且最豐富的蛋白質群。它們從構成糖萼的細胞表面膜糖蛋白,到白細胞產生的重要抗體。
磷蛋白
[edit | edit source]磷蛋白是指與含有磷酸的物質化學結合的蛋白質(有關更多資訊,請參閱磷酸化)。包括 Fc 受體、Ulks、鈣調神經磷酸酶、K 晶片和尿皮質素的類別。
金屬蛋白
[edit | edit source]包含金屬離子作為輔因子的蛋白質被稱為金屬蛋白。金屬蛋白在細胞中具有許多不同的功能,例如酶、轉運和儲存蛋白以及訊號轉導蛋白。事實上,大約四分之一到三分之一的所有蛋白質都需要金屬才能發揮其功能。金屬離子通常由屬於多肽鏈中氨基酸的氮、氧或硫原子以及摻入蛋白質中的大環配體進行配位。金屬離子的存在使金屬酶能夠執行氧化還原反應等功能,而這些功能不能輕易由氨基酸中發現的有限的功能基團集來執行。

| 金屬離子 | 含有該離子的酶的例子 |
|---|---|
| 鎂 | 葡萄糖-6-磷酸酶 己糖激酶 DNA 聚合酶 |
| 釩 | 釩結合蛋白 |
| 錳 | 精氨酸酶 |
| 鐵 | 過氧化氫酶 氫化酶 IRE-BP 順烏頭酸酶 |
| 鎳[41] | 脲酶 氫化酶 |
| 銅 | 細胞色素氧化酶 漆酶 |
| 鋅 | 醇脫氫酶 羧肽酶 氨基肽酶 β澱粉樣蛋白 |
| 鉬 | 硝酸還原酶 |
| 硒 | 谷胱甘肽過氧化物酶 |
| 各種 | 金屬硫蛋白 磷酸酶 |
血紅蛋白
[edit | edit source]血紅蛋白(或血紅素蛋白、血紅素蛋白),或血紅素蛋白,是一種含血紅素輔基的金屬蛋白,共價或非共價結合到蛋白質本身。血紅素中的鐵能夠進行氧化和還原(通常為 +2 和 +3,儘管在過氧化物酶中已知穩定的 Fe+4 甚至 Fe+5 物種)。血紅蛋白可能起源於一種原始策略,允許將血紅素的原卟啉 IX 環中所含的鐵 (Fe) 原子結合到蛋白質中。這種策略在進化過程中一直保持著,因為它使血紅蛋白對能夠結合二價鐵 (Fe) 的分子做出反應。這些分子包括,但可能不限於,氣體分子,例如氧氣 (O2)、一氧化氮 (NO)、一氧化碳 (CO) 和硫化氫 (H2S)。一旦與血紅蛋白的輔基血紅素基團結合,這些氣體分子可以以一種據說可以提供訊號轉導的方式調節這些血紅蛋白的活性/功能。因此,當在生物系統(細胞)中產生時,這些氣體分子被稱為氣體遞質。血紅蛋白含有含鐵的輔基,即血紅素。正是血紅素基團透過氧分子與血紅素基團中發現的鐵離子 (Fe2+) 的結合,將氧分子輸送到全身。[42]
血紅蛋白 血紅蛋白(也拼寫為血紅蛋白,縮寫為 Hb 或 Hgb)是所有脊椎動物[1](除魚類家族 Channichthyidae 外)紅血球和一些無脊椎動物組織中的一種含鐵的氧轉運金屬蛋白。血液中的血紅蛋白將氧氣從肺部或鰓部輸送到身體其他部位(即組織),在那裡釋放氧氣供細胞使用,並收集二氧化碳將其帶回肺部。在哺乳動物中,這種蛋白質約佔紅血球幹物質的 97%,約佔總含量的 35%(包括水)[需要引用]。血紅蛋白的氧氣結合能力為每克血紅蛋白 1.34 ml O2,這使血液的總氧氣容量增加了 70 倍。血紅蛋白參與其他氣體的運輸:它以氨基甲酸血紅蛋白的形式攜帶一些人體呼吸二氧化碳(約佔總量的 10%),其中 CO2 與珠蛋白結合。該分子還攜帶重要的調節分子一氧化氮,其結合到珠蛋白蛋白硫醇基團,在氧氣釋放的同時釋放它。血紅蛋白也存在於紅血球及其祖系之外。其他含有血紅蛋白的細胞包括黑質中的 A9 多巴胺能神經元、巨噬細胞、肺泡細胞和腎臟的系膜細胞。在這些組織中,血紅蛋白具有非氧氣轉運功能,作為抗氧化劑和鐵代謝調節劑。血紅蛋白和血紅蛋白樣分子也存在於許多無脊椎動物、真菌和植物中。在這些生物體中,血紅蛋白可以攜帶氧氣,或者可以作為二氧化碳、一氧化氮、硫化氫和硫化物的運輸和調節劑。這種分子的一個變體,稱為豆血紅蛋白,用於清除氧氣,以防止其毒害厭氧系統,如豆科植物的固氮結瘤。光敏色素,
細胞色素

一般來說,細胞色素是膜結合血紅蛋白,含有血紅素基團並進行電子傳遞。它們以單體蛋白(例如,細胞色素 c)或更大酶複合物的亞基形式存在,這些複合物催化氧化還原反應。它們存在於真核生物的線粒體內膜和內質網中,存在於植物的葉綠體中,存在於光合微生物和細菌中。
| 細胞色素 | 組合 |
| *a* 和 *a3* | 細胞色素 c 氧化酶(“複合物 IV”),電子透過可溶性細胞色素 c傳遞到複合物(因此得名) |
| *b* 和 c1 | 輔酶 Q - 細胞色素 c 還原酶(“複合物 III”) |
| *b6* 和 f | 質體醌醇 - 質體藍蛋白還原酶 |

| 型別 | 輔基 |
| 細胞色素 a | 血紅素 a |
| 細胞色素 b | 血紅素 b |
| 細胞色素 d | 四吡咯螯合物的鐵 |
視蛋白
[edit | edit source]視蛋白是一組對光敏感的 35-55 kDa 膜結合 G 蛋白偶聯受體,屬於視黃醛蛋白家族,存在於視網膜的光感受器細胞中。五組經典的視蛋白參與視覺,介導光子轉化為電化學訊號,這是視覺轉導級聯反應的第一步。另一種存在於哺乳動物視網膜中的視蛋白,黑視蛋白,參與晝夜節律和瞳孔反射,但不參與成像。
黃素蛋白
[edit | edit source]黃素蛋白是含有核黃素的核酸衍生物的蛋白質:黃素腺嘌呤二核苷酸 (FAD) 或黃素單核苷酸 (FMN)。黃素蛋白參與各種生物過程,包括但不限於生物發光、去除導致氧化應激的自由基、光合作用、DNA 修復和細胞凋亡。黃素輔因子的光譜特性使其成為活性位點內發生變化的天然報告器;這使得黃素蛋白成為研究最多的酶家族之一。
簡單蛋白質
[edit | edit source]水解後僅產生氨基酸的蛋白質稱為簡單蛋白質。
白蛋白
[edit | edit source]白蛋白(拉丁語:albus,白色)一般指任何水溶性蛋白質,在濃鹽溶液中中等溶解,併發生熱變性。它們通常存在於血漿中,並且在其他血漿蛋白中獨一無二,因為它們沒有糖基化。含有白蛋白的物質,例如蛋清,被稱為白蛋白類。
球蛋白
[edit | edit source]球蛋白是三種血清蛋白型別之一,另外兩種是白蛋白和纖維蛋白原。一些球蛋白在肝臟中產生,而另一些則由免疫系統產生。球蛋白一詞包含一組異質蛋白,其典型的分子量較高,溶解度和電泳遷移率均低於白蛋白。
組蛋白
[edit | edit source]在生物學中,組蛋白是存在於真核細胞核中的高度鹼性蛋白質,它們將 DNA 包裝並排列成稱為核小體的結構單元。它們是染色質的主要蛋白質成分,充當 DNA 纏繞的線軸,並在基因調控中發揮作用。
衍生蛋白
[edit | edit source]腖
[edit | edit source]腖是從動物乳汁或肉類中透過蛋白水解消化而得的。除了含有小肽外,所得的噴霧乾燥材料還包括脂肪、金屬、鹽、維生素和許多其他生物化合物。腖用於培養細菌和真菌的營養培養基
蛋白酶
[edit | edit source]蛋白酶自然存在於所有生物體中。這些酶參與許多生理反應,從簡單的食物蛋白質消化到高度調節的級聯反應(例如,血液凝固級聯反應、補體系統、細胞凋亡途徑和無脊椎動物前苯酚氧化酶啟用級聯反應)。蛋白酶可以根據蛋白質的氨基酸序列,要麼斷裂特定的肽鍵(有限蛋白水解),要麼將完整的肽分解為氨基酸(無限蛋白水解)。該活性可以是破壞性變化,消除蛋白質的功能或將其消化成主要成分;它可以是功能的啟用,或者可以是訊號通路中的訊號。
蛋白質資料庫或 PDB
[edit | edit source]蛋白質資料庫 (PDB) 的誕生源於兩股力量的匯聚,如同燃料和火焰:1) 一種規模雖小但不斷增長的蛋白質結構資料集,這些結構是透過 X 射線衍射法確定的;2) 1968 年問世的分子圖形顯示系統,布魯克海文光柵顯示器 (BRAD),用於三維觀察這些結構。1969 年,在布魯克海文國家實驗室的沃爾特·漢密爾頓博士的贊助下,埃德加·邁耶博士 (德克薩斯 A&M 大學) 開始編寫軟體,以通用格式儲存原子座標檔案,以便進行幾何和圖形評估。到 1971 年,程式 SEARCH 已遠端執行,用於提取和檢查結構資料,並因此成為網路啟動的關鍵因素,標誌著 PDB 的功能性起點。
漢密爾頓博士於 1973 年逝世,托馬斯·科茲爾博士接手 PDB 的領導工作,並在隨後的 20 年間一直擔任此職。1994 年 1 月,以色列魏茨曼科學研究所的約爾·薩斯曼博士被任命為 PDB 主任。1998 年 10 月,[43] PDB 轉移至結構生物資訊學研究合作中心 (RCSB);轉移於 1999 年 6 月完成。新任主任是來自羅格斯大學 (RCSB 成員機構之一) 的海倫·M·伯曼博士。[44] 2003 年,隨著 wwPDB 的成立,PDB 成為一個國際組織。創始成員包括 PDBe(歐洲)、RCSB(美國)和 PDBj(日本)。BMRB 於 2006 年加入。wwPDB 的四個成員都可以作為 PDB 資料的沉積、資料處理和分發中心。資料處理是指 wwPDB 工作人員審查和註釋每個提交的條目。然後自動檢查資料的合理性(該驗證軟體的原始碼已免費公開提供)。
蛋白質資料庫 (PDB)[45] 是大型生物分子(如蛋白質和核酸)的三維結構資料的儲存庫。(另請參閱晶體學資料庫)。這些資料通常透過 X 射線晶體學或核磁共振波譜獲得,由來自世界各地的生物學家和生物化學家提交,並透過其成員組織(PDBe、PDBj 和 RCSB)的網站在網際網路上免費獲取。PDB 由一個名為全球蛋白質資料庫 (wwPDB) 的組織監督。
胰島素
[edit | edit source]

在脊椎動物體內,胰島素的氨基酸序列非常保守。牛胰島素與人胰島素僅在三個氨基酸殘基上有所不同,而豬胰島素與人胰島素僅在單個氨基酸殘基上有所不同。甚至一些魚類的胰島素也與人胰島素足夠相似,可以在臨床上對人有效。一些無脊椎動物的胰島素在序列上也與人胰島素非常相似,並具有相似的生理作用。在不同物種的胰島素序列中觀察到的高度同源性表明,它在動物進化史上大部分時間裡都得到了保守。然而,胰島素原的 C 肽在不同物種間差異更大;它也是一種激素,但是一種次要激素。
胰島素在體內以六聚體(由六個胰島素分子組成)的形式生成並儲存,而活性形式是單體。六聚體是長期穩定的非活性形式,可以保護高反應性的胰島素,並使其隨時可用。六聚體與單體的轉化是胰島素注射製劑的核心方面之一。六聚體比單體穩定得多,這對實際應用來說是可取的,但單體是一種反應速度更快的藥物,因為擴散速率與粒徑成反比。反應速度快的藥物意味著胰島素注射不必在飯前數小時進行,從而使糖尿病患者在日常生活中更加靈活。胰島素可以聚集並形成纖維狀交錯的 β 片。這會導致注射澱粉樣變,並會阻止胰島素長時間儲存。[46]
1869 年,柏林的一名醫學生保羅·朗格漢斯在顯微鏡下研究胰腺結構時,發現了一些以前未發現的組織團塊散佈在胰腺的大部分割槽域。這些“小堆細胞”的功能尚不清楚,後來被命名為朗格漢斯島,但愛德華·拉蓋斯隨後提出,它們可能產生分泌物,在消化過程中發揮調節作用。保羅·朗格漢斯的兒子阿奇博爾德也幫助理解了這種調節作用。“胰島素”一詞源於拉丁語中的“insula”,意為小島或島嶼。1889 年,波蘭裔德國醫生奧斯卡·明可夫斯基與約瑟夫·馮·梅林合作,從一隻健康的狗身上切除了胰腺,以測試其在消化中的假定作用。在狗的胰腺被切除後的幾天裡,明可夫斯基的動物管理員注意到一群蒼蠅在狗的尿液上覓食。他們對尿液進行檢測後發現,狗的尿液中含有糖,從而首次確定了胰腺與糖尿病之間的關係。1901 年,尤金·奧皮取得了又一個重大進展,他明確地建立了朗格漢斯島與糖尿病之間的聯絡:糖尿病……是由朗格漢斯島的破壞引起的,只有當這些島體部分或全部被破壞時才會發生。在他進行這項工作之前,胰腺與糖尿病之間的聯絡是明確的,但朗格漢斯島的確切作用尚不清楚。
1923 年,諾貝爾獎委員會將胰島素的實際提取歸功於多倫多大學的一個團隊,並將諾貝爾獎頒給了兩位男性;弗雷德里克斯·班坦和 J.J.R. 麥克萊昂。他們在 1923 年因發現胰島素而獲得諾貝爾生理學或醫學獎。班坦對貝斯特沒有被提及感到不滿,他與貝斯特分享了他的獎項,而麥克萊昂也立即與詹姆斯·科利普分享了他的獎項。胰島素的專利以半美元的價格賣給了多倫多大學。
胰島素的一級結構由英國分子生物學家弗雷德里克·桑格確定。它是第一個被確定序列的蛋白質。他因這項工作獲得了 1958 年諾貝爾化學獎。1969 年,經過數十年的努力,多蘿西·克勞福特·霍奇金透過 X 射線衍射研究確定了該分子的空間構象,即所謂的三級結構。她因發展晶體學獲得了 1964 年諾貝爾化學獎。羅莎琳·薩斯曼·亞洛因開發了用於胰島素的放射免疫分析法,獲得了 1977 年諾貝爾醫學獎。[47]
參考文獻
[edit | edit source]- ↑ http://en.wikipedia.org/w/index.php?title=Protein&oldid=425576197
- ↑ http://en.wikipedia.org/w/index.php?title=Proteinogenic_amino_acid&oldid=420804587
- ↑ http://en.wikipedia.org/w/index.php?title=Amino_acid&oldid=425389108
- ↑ http://en.wikipedia.org/w/index.php?title=Amino_acid&oldid=425389108
- ↑ 光亮亮氨酸和光亮亮氨酸允許在活細胞中識別蛋白質-蛋白質相互作用。自然方法:4,261-7,2005
- ↑ http://en.wikipedia.org/w/index.php?title=Peptide_bond&oldid=417601014
- ↑ Basler B, Schuster O, Bach T (2005). “透過四氫呋喃酸醯胺的分子內 [2 + 2] 光環加成反應和隨後的內酯環開環製備構象受限的 β-氨基酸衍生物”. J. Org. Chem. 70 (24): 9798–808. doi:10.1021/jo0515226. PMID 16292808.
{{cite journal}}: 未知引數|month=被忽略 (幫助)CS1 maint: 多個名稱: 作者列表 (連結) - ↑ Murray JK, Farooqi B, Sadowsky JD; 等 (2005). “使用微波照射高效合成 β-肽組合庫”. J. Am. Chem. Soc. 127 (38): 13271–80. doi:10.1021/ja052733v. PMID 16173757.
{{cite journal}}: 在|author=中顯式使用“等” (幫助); 未知引數|month=被忽略 (幫助)CS1 maint: 多個名稱: 作者列表 (連結) - ↑ Seebach D, Matthews JL (1997). “β-肽:每一次都有驚喜”. Chem. Commun. (21): 2015–22. doi:10.1039/a704933a.
- ↑ http://en.wikipedia.org/w/index.php?title=Enzyme&oldid=424282616
- ↑ http://en.wikipedia.org/w/index.php?title=Enzyme&oldid=424282616
- ↑ Moss, G.P. "酶的命名法委員會建議". 酶的命名和分類的國際生物化學和分子生物學聯盟. 檢索於 2006-03-14.
- ↑ http://en.wikipedia.org/w/index.php?title=Enzyme&oldid=424282616
- ↑ Lovell SC; 等 (2003). “透過 Cα 幾何形狀進行結構驗證:φ,ψ 和 Cβ 偏差”. Proteins. 50 (3): 437–450. doi:10.1002/prot.10286. PMID 12557186.
{{cite journal}}: 在|author=中顯式使用“等” (幫助) - ↑ http://en.wikipedia.org/w/index.php?title=Protein_primary_structure&oldid=415921787
- ↑ Pauling L, Corey RB, Branson HR (1951). "蛋白質的結構:多肽鏈的兩種氫鍵螺旋構型". Proc Natl Acad Sci USA. 37 (4): 205–211. doi:10.1073/pnas.37.4.205. PMC 1063337. PMID 14816373.
{{cite journal}}: CS1 maint: 多個名稱: 作者列表 (連結) - ↑ Chiang YS, Gelfand TI, Kister AE, Gelfand IM (2007). “三明治狀蛋白質超二級結構的新分類揭示了鏈組裝的嚴格模式”. Proteins. 68 (4): 915–921. doi:10.1002/prot.21473. PMID 17557333.
{{cite journal}}: CS1 maint: 多個名稱: 作者列表 (連結) - ↑ RAMACHANDRAN GN, RAMAKRISHNAN C, SASISEKHARAN V (1963 年 7 月). “多肽鏈構型的立體化學”. J. Mol. Biol. 7: 95–9
- ↑ http://en.wikipedia.org/w/index.php?title=Alpha_helix&oldid=423162580
- ↑ 蛋白質三級結構和摺疊:第 4.3.2.1 節. 來自 蛋白質結構、比較蛋白質建模和視覺化的原理
- ↑ Hutchinson EG, Thornton JM (1993 年 4 月). “希臘鍵基序:提取、分類和分析”. Protein Eng. 6 (3): 233–45. doi:10.1093/protein/6.3.233. PMID 8506258.
- ↑ SCOP:摺疊:WW 結構域類似
- ↑ PPS '96 - 超二級結構
- ↑ Hutchinson, E. (1996). "PROMOTIF—A program to identify and analyze structural motifs in proteins". 蛋白質科學. 5 (2): 212–220. doi:10.1002/pro.5560050204. PMC 2143354. PMID 8745398.
{{cite journal}}: Cite has empty unknown parameter:|month=(help); Unknown parameter|coauthors=ignored (|author=suggested) (help) - ↑ Hutchinson EG, Thornton JM (1990). "HERA--a program to draw schematic diagrams of protein secondary structures". 蛋白質. 8 (3): 203–12. doi:10.1002/prot.340080303. PMID 2281084.
- ↑ http://en.wikipedia.org/w/index.php?title=Coiled_coil&oldid=427735447
- ↑ Steven Bottomley (2004). "互動式蛋白質結構教程". Retrieved January 9, 2011.
{{cite web}}: Check|authorlink=value (help); External link in|authorlink= - ↑ http://en.wikipedia.org/w/index.php?title=Protein_tertiary_structure&oldid=422486540
- ↑ http://en.wikipedia.org/wiki/Protein_quaternary_structure
- ↑ Crowfoot Hodgkin D (1935). "胰島素的X射線單晶照片". 自然. 135: 591. doi:10.1038/135591a0.
- ↑ Kendrew J. C.; et al. (1958-03-08). "透過X射線分析獲得的肌紅蛋白分子三維模型". 自然. 181 (4610): 662. doi:10.1038/181662a0. PMID 13517261.
{{cite journal}}: Explicit use of et al. in:|author=(help) - ↑ "PDB 中的條目表,按實驗方法排列".
- ↑ "PDB 統計". RCSB 蛋白質資料庫. Retrieved 2010-02-09.
- ↑ Scapin G (2006). "結構生物學與藥物發現". Curr. Pharm. Des. 12 (17): 2087. doi:10.2174/138161206777585201. PMID 16796557.
- ↑ Lundstrom K (2006). "膜蛋白的結構基因組學". 細胞與分子生命科學. 63 (22): 2597. doi:10.1007/s00018-006-6252-y. PMID 17013556.
- ↑ Lundstrom K (2004). "膜蛋白的結構基因組學:簡要綜述". 組合化學與高通量篩選. 7 (5): 431. PMID 15320710.
- ↑ http://en.wikipedia.org/w/index.php?title=Protein_sequencing&oldid=413170994
- ↑ Niall HD (1973). "自動艾德曼降解:蛋白質測序儀". Meth. Enzymol. 27: 942–1010. doi:10.1016/S0076-6879(73)27039-8. PMID 4773306.
- ↑ http://en.wikipedia.org/w/index.php?title=Protein_sequencing&oldid=413170994
- ↑ http://en.wikipedia.org/w/index.php?title=Protein_sequencing&oldid=413170994
- ↑ Astrid Sigel, Helmut Sigel 和 Roland K.O. Sigel,編輯 (2008). 鎳及其在自然界中令人驚訝的影響. 生命科學中的金屬離子. 卷 2. 威利. ISBN 978-0-470-01671-8.
- ↑ http://en.wikipedia.org/w/index.php?title=Hemeprotein&oldid=410476687
- ↑ Berman, H. M. (2000). "蛋白質資料庫". Nucleic Acids Res. 28 (1): 235–242. doi:10.1093/nar/28.1.235. PMC 102472. PMID 10592235.
{{cite journal}}: 未知引數|coauthors=被忽略 (|author=建議) (幫助); 未知引數|month=被忽略 (幫助) - ↑ "RCSB PDB 新聞通訊存檔". RCSB 蛋白質資料庫.
- ↑ wwPDB, Consortium (2019). "蛋白質資料庫:全球唯一的 3D 大分子結構資料存檔". Nucleic Acids Res. 47 (D1): 520–528. doi:10.1093/nar/gky949. PMC 6324056. PMID 30357364.
{{cite journal}}: 未知引數|month=被忽略 (幫助) - ↑ http://en.wikipedia.org/w/index.php?title=Insulin&oldid=425481933
- ↑ http://en.wikipedia.org/w/index.php?title=Insulin&oldid=425481933