
統計分析:使用 R 的入門 / 第 1 章
圖 1.1 顯示了 R 統計包中可用的標準資料集之一。在 1920 年代,記錄了以不同速度行駛的汽車的制動距離。分析速度和制動距離之間的關係可以透過更改超速法律、汽車設計等影響大量人的生活。其他資料集,例如有關醫療或環境資訊的資料集,對人類以及我們對世界的理解有著更大的影響。但現實世界中的資料通常是“混亂的”,如該圖所示。大多數人看到該圖後很樂意得出結論,即速度和制動距離之間存在某種聯絡。然而,這不可能是全部故事,因為即使是在相同速度下,也會記錄不同的制動距離。

這種直覺上合理的模式和混亂的組合也許是科學結果中最常見的現象之一。統計分析可以幫助我們澄清和判斷我們認為看到的模式,以及從混亂中揭示可能難以辨別的影響。它可以用作解釋我們周圍世界的工具,也許同樣重要的是,它可以用來說服他人我們解釋的正確性。這種對明智判斷和說服他人的強調很重要:理想情況下,統計學應該幫助清晰地解釋,而不是靠論據來強迫。
關於統計分析的一個常見誤解是,它必然是技術性的並且“難以理解”。事實上,“我不懂統計學”是一個經常聽到的感嘆。但如果一項分析只能被統計學家理解,那麼它在很大程度上已經失敗了。為了讓一項分析說服受眾,應該仔細、全面地給出一種或多種對特定情況的合理解釋。然後可以利用對資料的統計分析(理想情況下,這些資料已被收集用於檢驗這些解釋)來證明一個可以普遍接受的結論。作為一項規則,解釋越簡單——越 簡約——就越值得優先考慮。因此,一個好的解釋是,對於一位見多識廣的觀察者來說,它是合理的、可理解的,它可以做出明確的預測,但儘可能地簡單。
本書旨在教你如何以統計的方式來制定和檢驗這樣的“解釋”。這是統計分析的基礎。
與它具有許多相似之處的“科學方法”一樣,是否存在一個普遍的“統計方法”[需要引用]也存在爭議。然而,大多數統計分析都涉及質疑世界某一方面,提出對這些問題的潛在答案,然後透過提出統計模型來正式化這些解釋,這些模型可以解釋資料的特定方面。
因此,分析的三個主要部分是
- 決定你想要解決的問題(或者更籠統地說,分析的目標)
- 提出一些合理的解釋,這些解釋有可能回答這些問題
- 將這些解釋形式化為統計模型
- 收集適當的資料
- (使用或多或少的技術方法)使用資料檢驗模型。
例如***
因此,你可能執行的大多數分析都顯式或隱式地假設了潛在的“統計模型”。因此,理解統計模型以及它們所包含的內容對於理解統計學至關重要。
第 3 章將更詳細地討論統計模型,但在這裡介紹一些一般概念是值得的。模型提供一些預測***。區別統計模型的是,該過程中也存在不確定性。因此,統計模型由兩個組成部分組成:一個是固定的,另一個是捕捉不確定性的。這是
例如,我們可以回到圖 1.1 中描述的情況。我們會多次回顧的一點是,對資料背景或上下文的良好理解對於任何分析都是必不可少的。在這種情況下,瞭解資料與汽車的速度和制動距離有關非常重要。我們關於駕駛的一般知識可以指導我們選擇模型。特別是,我們可能猜測,假設速度對制動距離有影響(而不是相反)似乎是合理的。將速度視為由其他因素決定,並且超出了我們分析範圍似乎是合理的***。
因此,一個初始的、合理的模型可能會假設制動距離由速度加上某種隨機誤差決定。為了精確地建模,為了根據一組速度構建一組假想的制動距離,我們需要更加精確。特別是,我們需要指定速度如何影響距離,以及誤差是什麼樣子***。
稍後我們將看到如何用數學方式指定這一點。目前,我們將用圖形和模擬的方式來完成
通常假設“正態”誤差 ****
例如,也許根本沒有影響:無論速度如何,制動距離都是固定的:距離變化的唯一原因是由於隨機誤差。=> 用圖形顯示
我們需要比這更精確:我們
統計模型中最重要的方面之一是,當模型在圖 1.2(a-d)中顯示時,這是合理的。在所有四個圖形中,都提出了不同的統計模型:每個模型的預測部分用紅色線顯示,不確定性(歸因於機會或誤差的波動)用淺藍色線顯示。在所有情況下,該模型都假設不確定性全部存在於制動距離的影響中(淺藍色線全部是垂直的)。
為了單獨顯示不確定性,每個圖形中的右側圖形顯示了殘差***。
- 圖 1.2:適合圖 1.1 中資料的各種統計模型
-
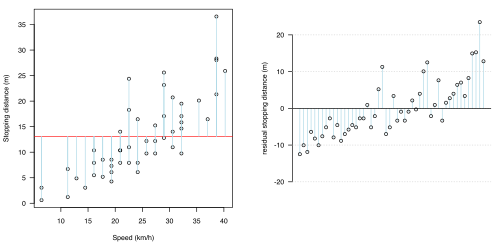 (a)無關聯
(a)無關聯 -
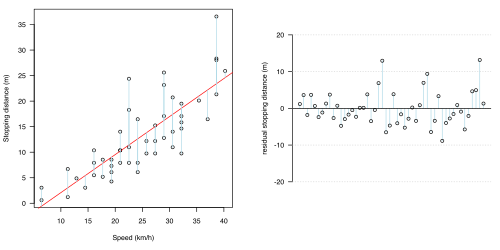 (b)直線
(b)直線 -
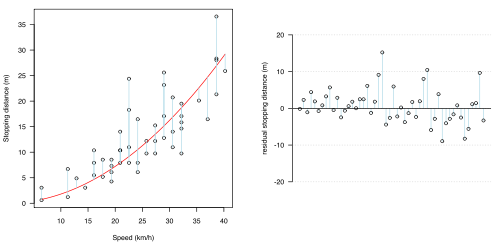 (c)平方(簡單二次)關係
(c)平方(簡單二次)關係 -
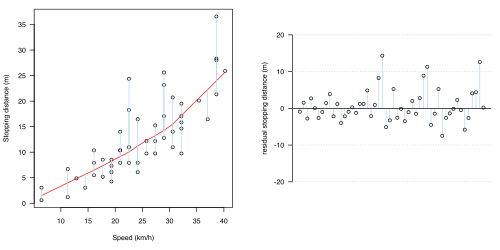 (d)使用區域性平滑(LoWeSS)擬合
(d)使用區域性平滑(LoWeSS)擬合




* 直線(橙色)。線性關係可能是解釋之間的關係的最簡單方法,這就是為什麼***。對該模式的最簡單解釋是,制動距離與速度成正比,因此,每增加一英里/小時,制動距離就會增加一個固定量:在圖形上,這表示圖上的直線。這很常見。
- 曲線(紅色)。然而,這還沒有考慮到任何 : 也許。如前所述,這不足以解釋所有資料:可能不清楚 lowess 是一個模型 ****。
“cars”示例突出了在進行統計時,事先了解資訊的重要性。資料不應該被視為純粹的“數字”,而應該在上下文中考慮。在這裡,因為我們知道資料是相對容易理解的物理系統的結果,所以我們應該被引導著問是否期望特定的關係,這會鼓勵我們使用簡單的二次擬合。
因此,在任何分析中,瞭解資料至關重要:瞭解它們從哪裡來,它們如何與現實世界相關,以及——透過繪圖或其他形式的“探索性資料分析”——它們是什麼樣子。事實上,繪製資料是統計分析中最基本的技術之一:它是一個揭示模式並說服他人的強大工具。如果有必要,可以使用更正式的數學技術來對其進行補充。本書中使用圖形的目的有兩個:它們不僅可以用於探索資料,而且正式的統計方法通常可以透過圖形方式來理解和描繪,而不是大量使用數學。這是本書的主要目標之一。
包
一些包應該始終在 R 中可用,並且其中許多在 R 會話開始時自動載入。這些包括“base”包(其中定義了max()和sqrt()函式)、“utils”包(其中定義了RSiteSearch()和citation())、“graphics”包(允許生成繪圖)以及“stats”包(提供廣泛的統計功能)。總的來說,預設包允許您進行大量的統計分析。
library()函式將其載入到 R 中。library("datasets") #Load the already installed "datasets" package
cars #Having loaded "datasets", the "cars" object (containing a set of data) is now available
library("vioplot") #Try loading the "vioplot" package: will probably fail as it is not installed by default
install.packages("vioplot") #This is one way of installing the package. There are other ways too.
library("vioplot") #This should now work
example("vioplot") #produces some pretty graphics. Don't worry about what they mean for the time being> library(datasets) # 載入資料集包(實際上,它可能已經被載入了) > cars # 顯示其中一個數據集:有關更多資訊,請參閱 ?car
speed dist
1 4 2 2 4 10 3 7 4 4 7 22 5 8 16 6 9 10 7 10 18 8 10 26 9 10 34 10 11 17 11 11 28 12 12 14 13 12 20 14 12 24 15 12 28 16 13 26 17 13 34 18 13 34 19 13 46 20 14 26 21 14 36 22 14 60 23 14 80 24 15 20 25 15 26 26 15 54 27 16 32 28 16 40 29 17 32 30 17 40 31 17 50 32 18 42 33 18 56 34 18 76 35 18 84 36 19 36 37 19 46 38 19 68 39 20 32 40 20 48 41 20 52 42 20 56 43 20 64 44 22 66 45 23 54 46 24 70 47 24 92 48 24 93 49 24 120 50 25 85 > library(vioplot) # 嘗試載入“vioplot”包:這可能會失敗,因為它不是預設安裝的 錯誤: 在 library(vioplot) 中: 沒有名為 ‘vioplot’ 的包 > install.packages("vioplot") # 這是安裝包的一種方法。還有其他方法。 同時安裝依賴項 ‘sm’
嘗試 URL 'http://cran.uk.r-project.org/bin/macosx/universal/contrib/2.8/sm_2.2-3.tgz' 內容型別 'application/x-gzip' 長度 306188 位元組 (299 Kb) 已開啟 URL
=======================
已下載 299 Kb
嘗試 URL 'http://cran.uk.r-project.org/bin/macosx/universal/contrib/2.8/vioplot_0.2.tgz' 內容型別 'application/x-gzip' 長度 9677 位元組 已開啟 URL
=======================
已下載 9677 位元組
已下載的包位於 /tmp/RtmpR28hpQ/downloaded_packages > library(vioplot) # 這現在應該可以工作 載入所需的包:sm 包 `sm`,版本 2.2-3;版權所有 (C) 1997、2000、2005、2007 A.W.Bowman & A.Azzalini 鍵入 help(sm) 以獲取摘要資訊 > example(vioplot) # 生成一些漂亮的圖形。暫時不必擔心它們的意思
vioplt> # 箱線圖與小提琴圖 vioplt> par(mfrow=c(2,1))
vioplt> mu<-2
vioplt> si<-0.6
vioplt> bimodal<-c(rnorm(1000,-mu,si),rnorm(1000,mu,si))
vioplt> uniform<-runif(2000,-4,4)
vioplt> normal<-rnorm(2000,0,3)
vioplt> vioplot(bimodal,uniform,normal) 按 <回車> 檢視下一張圖
vioplt> boxplot(bimodal,uniform,normal)
vioplt> # 新增到現有圖中 vioplt> x <- rnorm(100)
vioplt> y <- rnorm(100)
vioplt> plot(x, y, xlim=c(-5,5), ylim=c(-5,5)) 按 <回車> 檢視下一張圖
vioplt> vioplot(x, col="tomato", horizontal=TRUE, at=-4, add=TRUE,lty=2, rectCol="gray")
vioplt> vioplot(y, col="cyan", horizontal=FALSE, at=-4, add=TRUE,lty=2)
install.packages()以這種方式安裝包,也應該安裝依賴項[1]。還有幾種其他安裝包的方法。如果您透過在 Unix 命令列上鍵入“R”來啟動 R,那麼您可以透過從命令列執行“R CMD INSTALL packagename”來安裝包(請參閱?INSTALL)。如果您使用圖形使用者介面(例如在 Macintosh 或 Windows 下)執行 R,那麼您通常可以透過使用螢幕選單來安裝包。請注意,這些方法可能無法安裝其他依賴包。
您只需要在安裝包時遇到問題時才需要閱讀以下內容。 如果一個包還沒有安裝,並且您在嘗試安裝它時遇到問題(例如,當呼叫 install.packages("vioplot")時),這可能是由於以下原因之一
|
圖形
在 R 中生成繪圖有兩種主要方法
- 傳統的 R 圖形。這個基本的圖形框架是我們將在本主題中介紹的內容。我們將使用它來生成與圖 1.1 和 1.2 中相似的繪圖。
- “Trellis”圖形。這是一種更復雜的框架,適用於在一頁上生成多個類似的繪圖。在 R 中,此功能由“lattice”包提供(鍵入
help("Lattice", package=lattice)以獲取詳細資訊)。
如何在後面的章節中生成特定型別的繪圖的詳細資訊;本主題僅介紹最基本原理,其中有三個主要原理需要注意
- 在 R 中,繪圖是透過鍵入特定的圖形命令來生成的。這些命令有兩種型別
- 設定完全新繪圖的命令。此型別最常見的函式稱為
plot()。在最簡單的情況下,這可能會用新的繪圖替換任何以前的繪圖。 - 向現有繪圖新增圖形(線條、文字、點等)的命令。許多函式可以做到這一點:最有用的函式是
lines()、abline()、points()和text()。
- 設定完全新繪圖的命令。此型別最常見的函式稱為
- R 始終將圖形輸出到裝置。通常這是螢幕上的一個視窗,但它可以是 pdf 或其他圖形檔案(可以在
?device中找到完整列表)。這是將繪圖儲存到文件等中的一種方法。要將圖形儲存到(例如)pdf 檔案中,您需要使用pdf()啟用新的 pdf 裝置,執行您的正常圖形命令,然後使用dev.off()關閉裝置。這在下述最後一個示例中進行了說明。 - 根據
plot()的第一個引數,會觸發不同的函式。預設情況下,這些函式旨在生成合理的結果。例如,如果它接受一個函式,例如sqrt函式,plot()將生成x對sqrt(x)的圖形;如果它接受一個數據集,它將嘗試以合理的方式繪製資料點(有關更多詳細資訊,請參閱?plot.function和?plot.data.frame)。諸如顏色、樣式和專案大小以及軸標籤、標題等圖形細節,可以透過plot()函式的進一步引數來控制[3]。
plot(sqrt) #Here we use plot() to plot a function
plot(cars) #Here a dataset (axis names are taken from column names)
###Adding to an existing plot usually requires us to specify where to add
abline(a=-17.6, b=3.9, col="red") #abline() adds a straight line (a:intercept, b:slope)
lines(lowess(cars), col="blue") #lines() adds a sequence of joined-up lines
text(15, 34, "Smoothed (lowess) line", srt=30, col="blue") #text() adds text at the given location
text(15, 45, "Straight line (slope 3.9, intercept -17.6)", srt=32, col="red") #(srt rotates)
title("1920s car stopping distances (from the 'cars' dataset)")
###plot() takes lots of additional arguments (e.g. we can change to log axes), some examples here
plot(cars, main="Cars data", xlab="Speed (mph)", ylab="Distance (ft)", pch=4, col="blue", log="xy")
grid() #Add dotted lines to the plot to form a background grid
lines(lowess(cars), col="red") #Add a smoothed (lowess) line to the plot
###to plot to a pdf file, simply switch to a pdf device first, then issue the same commands
pdf("car_plot.pdf", width=8, height=8) #Open a pdf device (creates a file)
plot(cars, main="Cars data", xlab="Speed (mph)", ylab="Distance (ft)", pch=4, col="blue", log="xy")
grid() #Add dotted lines to the pdf to form a background grid
lines(lowess(cars), col="red") #Add a smoothed (lowess) line to the plot
dev.off() #Close the pdf device


一個簡單的 R 會話
a ~ b + c 的符號,表示 a 由 b 和 c 預測)。plot(dist ~ speed, data=cars) #A common way of creating a specific plot is via a model formula
straight.line.model <- lm(dist~speed, data=cars) #This creates and stores a model ("lm" means "Linear Model").
abline(straight.line.model, col="red") #"abline" will also plot a straight line from a model
straight.line.model #Show model predictions (estimated slope & intercept of the line)
科學方法
[edit | edit source]統計學家不能逃避搞清楚科學推理原則的責任,同樣地,任何其他思考的人也不能逃避類似的義務。——R. A. Fisher
本書重點介紹統計學在 科學方法 中的重要作用。從根本上說,科學涉及仔細測試一系列合理的解釋,或者說是“假設”,這些解釋聲稱解釋觀察到的現象。通常,這是透過提出合理的假設,然後嘗試透過仔細的實驗或資料收集來消除其中一個或多個假設來完成的(這被稱為 假設演繹法)。這意味著對科學假設的基本要求是它可以被證明是錯誤的:用 Popper 的話來說,它是“可證偽的”。在本章中,我們將看到邏輯上不可能“證明”一個假設是正確的;儘管如此,一個假設透過的測試越多,我們就越應該相信它。
理想情況下,科學研究涉及一個重複的過程,包括生成假設、消除儘可能多的假設,並提煉剩餘的假設,這個過程被稱為“強推斷”(引用 Platt)。這裡涉及兩個截然不同的步驟:一個相當推測性的步驟,其中生成或提煉假設,以及一個嚴格邏輯性的步驟,其中消除假設。
這兩個步驟在統計分析中都有其對應物。與假設檢驗有關的統計分支旨在識別哪些假設似乎不太可能,因此可能被消除。與探索性分析有關的統計分支旨在識別資料集的合理解釋。雖然我們將分別開始討論這些技術,但應強調,在實踐中,這種區別並不那麼明確。統計實踐的這兩個分支最好被視為研究人員可用的技術連續譜的兩個極端。例如,許多假設涉及數值引數,例如最佳擬合線的斜率。對這些引數的統計估計可以被視為對假設的檢驗,但也可以被視為對事實的提煉或甚至新穎解釋的建議。
假設檢驗
[edit | edit source]為了適當地檢驗一個假設,需要收集正確型別的資料。事實上,有針對性地收集資料和(如果可能)仔細設計實驗,可能是科學中最重要的過程。這並不難。例如,假設我們的假設是(由於遺傳原因)一個人不可能同時擁有金髮和棕色眼睛。這個假設可以透過對擁有這種特徵組合的人的單一觀察來反駁。
Eye Hair Brown Blue Hazel Green Black 68 20 15 5 Brown 119 84 54 29 Red 26 17 14 14 Blond 7 94 10 16 |
表 1.1 顯示了 1974 年對特拉華大學學生的一項調查的結果[4]。與任何測試一樣,我們需要對這些資料做出一些假設,例如,染髮學生沒有被包括在內,或者列在了他們原來的頭髮顏色下。如果是這樣,那麼我們可以立即看到,我們可以拒絕金髮&棕色:不可能的假設:有 7 名學生有棕色眼睛和金髮[5]。
但是,想象一下,如果調查沒有發現任何棕色眼睛和金髮的學生。雖然這與我們的假設一致,但它不足以證明它是正確的。可能是棕色眼睛和金髮非常罕見,我們沒有看到任何人是純粹的巧合。這是一個普遍的問題。不可能確定一個假設是正確的:可能總會有另一個非常相似的解釋來解釋相同的觀察結果。
然而,正如在這個例子中看到的,可以拒絕假設。因此,科學依靠消除假設。因此,科學家經常構建一個或多個他們認為不是這樣,僅僅是為了被拒絕的假設。如果一項研究的目的是讓人們相信一個特定的理論或假設,那麼一個好的方法是定義包含儘可能多的可以預見的合理的替代解釋的假設。如果所有這些都可以被反駁,那麼剩下的原始假設就會更有說服力。
零假設
[edit | edit source]在大多數科學觀察中,都存在一定程度的偶然性[6],因此嘗試消除的最重要的假設——至少最初——是觀察到的資料僅僅是由於偶然因素造成的。這通常被稱為零假設。
在我們最初的例子中,零假設相對明顯:它是頭髮和眼睛顏色之間沒有關聯(任何看似關聯的都是純粹的巧合)。但是,構建一個合適的零假設並不總是那麼容易。以下是我們將在後面研究的三個例子,從簡單到高度複雜不等。
- 醫院出生的孩子的性別比例(例如,1997 年 12 月 18 日在澳大利亞布里斯班的 Mater Mother's 醫院,出生了 44 個孩子[7],其中 18 個是女性)。一個合理的零假設可能是,無論性別如何,男性和女性的可能性都相同。由於已知人類通常具有男性偏向的性別比例,因此不同的零假設(例如 51% 的男性)可能更合理。
- 圖 1.1 中看到的汽車速度和停車距離之間的關係。一個合理的零假設可能是,汽車的速度與其停車距離之間沒有關係。但是,汽車停車距離(x 和 y 之間沒有“關聯”) - 更難,因為誤差分佈未知。以下是一種方法:例如,可以取 x 的秩和 y 的秩。或者抽樣。
在這兩種情況下,我們都需要*建模*零假設:如果
- 英國 1969-1985 年汽車死亡和重傷人數。 圖 1.2 顯示安全帶 **** 更復雜的零模型 - 例如安全帶 - 如果我們擬合一條直線,我們需要對該線的變化做出一些假設。或者我們可以將實際值視為代表該變化。這是一個更復雜的模型,影響了英國大部分人口,即 1983 年 1 月 31 日生效的強制使用汽車安全帶的法律。零模型涉及其他因素(例如汽油價格)
{kind=link}
只要有足夠的資訊,我們就可以對零假設進行建模。**針對不同示例需要什麼**。由於存在隨機誤差,我們需要多次這樣做。我們將看到,許多統計學都依賴於根據零假設給出類似於觀察結果的頻率來拒絕零假設。
其他情況也是一樣,例如安全帶???比較模型


假設可能不是簡單的“是”或“否”問題,而是更復雜的,例如:
資料表明的性別比例是多少?(這很簡單,但我們對這個估計的準確性有多大信心?)
汽車:我們相信速度和剎車距離之間存線上性關係:線的斜率是多少(但也許物理學表明不同的關係 - 直線通常是預設值) - 這裡我們已經做出了一些模型選擇。
MLE 簡要描述“如果模型是正確的,這些引數的最可能值是什麼?”
有無數的模型存在。結合良好的理解和/簡約性/,可以用來構建假設和*模型*。DF?
例如,是否有比直線擬合更好的想法?
這是否合理(例如,如果不能小於 0)
安斯庫姆
異常值???殘差(可能不是)
互動作用怎麼樣?泰坦尼克號的性別與等級?
使用顏色來區分型別
人眼擅長髮現模式(但......即使沒有模式)。例如,時間序列
即使我們有預測(模型),它與假設的擬合程度如何?
哪些是重要的(與顯著因素相反)因素?
應該有足夠的背景來描述來自[[2]]
每個實驗只是一個數據點嗎?等等?
- ↑ 實際上,細節稍微複雜一些,取決於是否有一個預設位置來安裝軟體包,請參見
?install.packages - ↑ 目前還沒有介紹足夠的 R 來完全解釋本章中使用的繪圖命令。不過,對於那些感興趣的人來說,對於任何繪圖,用於生成它的命令都列在影像摘要中(可以透過點選影像檢視)。
- ↑ 不幸的是,可用的眾多引數的細節(其中許多是其他圖形生成例程共有的)散佈在多個幫助檔案中。例如,要檢視對資料集呼叫時
plot()的選項,請參見?plot、?plot.default和?par。要檢視對函式呼叫時plot()的選項,請參見?plot.function。在幫助檔案中列出了用於指定各種繪圖符號的pch引數的數字points()(用於向繪圖新增點的函式):可以透過example(points)檢視它們。 - ↑ 來自 Snee (1974) The American Statistician, 28, 9–12。完整的參考文獻可以在 R 中透過輸入 ?HairEyeColor 找到。此處的表格已在性別上彙總,如
example(HairEyeColor)
- ↑ 當假設很簡單並且只有少量資料像這樣時,以表格形式呈現它通常與繪圖一樣有用
- ↑ 這可能是真正的隨機,也可能是由於我們不知道的因素造成的
- ↑ 見[[1]]