
Conlang/高階/語法/支配
此材料存在一些重大問題;請參閱 討論頁面. |
句法是句子的結構如何以及為何這樣:句子元素之間的關係以及這些關係編碼的內容。它是一種語言將意義片段組織成對世界、想法、情景等的表示的方式。沒有句法,就無法將任何特定的意義放入聲音或符號中,也無法從聲音或符號中獲取任何特定的意義。簡而言之,沒有句法,就沒有語言,就像沒有有意義的成分,就沒有語言一樣。
詞序影響語法的一些例子
- 1) 狗咬了人。
- 2) 狗是棕色的。
- 3) *人咬了狗。
- 4) *狗是棕色的。
詞序影響意義的一些例子
- 5) 人咬了狗。
- 6) 狗咬了人。
- 7) 狗是棕色的嗎?
[注意:句子前的星號表示語法錯誤。句子前的上標問號表示語法存疑或未知,或者只對某些說話者有效。]
句法一般描述兩件事:某些東西可以放在哪裡,以及這些位置意味著什麼。在這個層面上,我們將觀察各種語言,比較它們實現相同目標的不同方式。稍後,在高階句法教程中,我們將回過頭來嘗試找出是否可以使用相同的句法基本規則和結構來描述所有語言,以及為什麼它們看起來如此不同。
與更簡單的句法方法不同,本教程將深入探討語言學理論。傳統方法只是討論像SOV vs. SVO vs. 等詞序之類的事情,本教程將探討產生這些詞序的底層結構和規則。在高階句法教程中,我們將看到我們制定的規則如何更清楚地闡明這種情況,並促使我們拋棄SOV vs. SVO vs. 等詞序作為句法中基本概念的簡單概念。
本教程將介紹句法中使用的一些初步概念,主要是句子的結構成分。正如我們將在教程結束時看到的那樣,我們可以用這種方法解釋語言的大量特徵,但我們仍然遺漏了語言實際產生的內容中的很大一部分。高階句法教程將帶我們進入新的領域,探索一些旨在解釋更多語言的理論。本教程和高階句法教程都將遵循Andrew Carnie的《句法:生成性導論》(第二版)的總體結構,可以看作是針對構詞者的該書摘要。如果您認真想從P&P的角度理解句法,強烈推薦這本書。
本節的組成部分是
- 詞性: 詞彙屬於哪些類別?
- 成分、樹、規則: 詞彙如何組合?
- 結構關係: 詞彙和組合如何相互關聯?
- 綁定理論: 為什麼代詞看起來行為很奇怪?
- 語言學普遍性: 各種語言的句法如何模式化?
- 應用知識: 如何在創造語言時應用這些知識?
- 找出問題: 該理論中還存在哪些問題?
眾所周知,句子是由詞彙構成的。但並非所有詞彙都一樣;一些詞彙代表物體,一些詞彙代表動作,等等。一個詞彙代表什麼——它的詞性或句法類別——在它在語言句法中的行為中起著重要作用。我們可以識別出詞彙的兩大類。詞彙詞性本身就傳達完整的意義,包括名詞和動詞等類別。另一方面,功能詞性顯示詞彙之間的關係,或者為詞彙提供額外的意義,包括介詞和連線詞等類別。
詞彙詞性可以分為四大類:名詞(N)、動詞(V)、形容詞(Adj)和副詞(Adv)。這些類別不一定是普遍存在的,它們彼此之間的區別在於它們的行為方式。將一個詞彙識別為名詞或動詞是透過觀察它做了什麼來完成的:一個詞彙是名詞,因為它像名詞一樣表現,等等。這些特定類別是針對英語和許多印歐語系的,由於本教程是英文的,並且主要關注英語句法,因此將使用這些類別。
在非正式的或小學英語語法中,描述名詞的典型方法是“人、地點或事物”。名詞也可以是情緒、顏色、抽象概念,等等。名詞通常可以有數量、特指性、形容詞顯示的屬性、動作中的角色,等等。
動詞通常表示動作,涉及某種變化,或表示存在狀態,涉及一種存在方式與另一種存在方式的比較。它們通常可以描述為具有時態(發生時間)、體(透過時間發生的事件)、由副詞表示的方式、由名詞和其他短語表示的參與者等。
形容詞
[edit | edit source]形容詞描述名詞的屬性。它們可以表示顏色、形狀,或更抽象的屬性,如真實、誠實或荒謬。形容詞本身可以具有品質或方式,由副詞描述。
副詞
[edit | edit source]副詞描述非名詞的屬性,即動詞、形容詞和其他副詞。它們可能是詞彙類別中最抽象的。例如,“快速”是一個描述動詞速度的副詞,但在動作中沒有可以測量的快速性,它是一個與紅色這樣的屬性相比非常抽象和相對的概念。像“非常”這樣的副詞更加抽象。
功能性
[edit | edit source]功能類別比最抽象的副詞更難概念化。它們傳達了動詞的時態、能力、許可和體,短語之間的關係,名詞的特指性等。英語中一些常見的功能類別是介詞(P)、限定詞(D)、連線詞(Conj)、補語引導詞(C)、時態(T)和否定(Neg)。
特徵
[edit | edit source]特徵是抽象的語義屬性,可以用來描述單詞。一些屬性,如複數性,沒有其他屬性那麼抽象,如模態。它們傾向於成為有關單詞的額外資訊,與句子的結構相關,支配著單詞與周圍其他單詞之間的關係。特徵通常寫在方括號內。具有特徵用在特徵前新增“+”表示,缺少特徵用在特徵前新增“–”表示。多個特徵用逗號分隔。
一些特徵示例
- [+plural]
- [–definite]
- [+past,+inchoative]
- [+Q,–WH]
在高階教程中,我們將看到特徵本身如何用詞彙表示,以及特徵如何存在於某些地方並影響句子中單詞的行為以傳達某些含義。
在研究各種型別的詞的行為時,我們發現它們最終被分成各種類別,這些類別支配著它們在句子中的放置方式。在某些語言中,這些子類別可以在詞上顯式標記(例如,西班牙語有顯式標記的性別子類別,這支配著動詞的語態一致),而在另一些語言中,子類別是隱式的,並且沒有顯示其所屬子類別的任何標記。
在英語中,名詞可以分為兩類,可數名詞,表示單個可數的專案,和不可數名詞,表示不可數的事物或物質。可數名詞需要數量指示,而不可數名詞不需要。
- *Dog bit the man.
- A dog bit the man.
- The dog bit the man.
- Dogs bit the man.
可數名詞只能與某些量詞一起使用,而不可數名詞則與另一些量詞一起使用
- many cats
- *much cats
- much water
- *many water
如果我們想用子類別標記這些名詞,可以用特徵來標記。例如,可數名詞和不可數名詞之間的區別可以用特徵 [±count] 來標記。
- dog[+count]
- cat[+count]
- water[-count]
動詞子類別
[edit | edit source]我們還可以看一下英語中動詞的一些子類別。透過檢查動詞接受的引數數量,以及它們在句子中的位置,我們可以發現動詞的一些有用屬性。
僅僅透過檢視動詞接受的引數數量(其價態),我們就能在英語中找到三種動詞。不及物動詞只接受一個引數,即主語,及物動詞接受兩個引數,即主語和直接賓語,雙及物動詞接受三個引數,即主語、直接賓語和間接賓語。一些動詞似乎具有可選的及物性,例如動詞“drive”:你可以說“I drive.”,但你也可以說“I drive a car.”。在這種情況下,我們可以說實際上有兩個具有不同價態的動詞。
動詞也可能在句子中相對於它們的位置要求某些特定的東西。不及物動詞要求它們的引數在它們之前。我們可以用一個特徵來表示這一點,例如 [NP __],下劃線表示動詞的位置,NP 表示Noun Phrase。及物動詞要求它們的 引數在它們之前和之後,這可以用特徵 [NP __ NP] 或 [NP __ {NP/CP}](CP 表示Complement Phrase)表示。花括號包含可選的選項,用斜槓分隔。我們說一些及物動詞的賓語可以是 NP 或 CP,因為我們有以下例子:“I said nothing.”,以及“I said that the pie was tasty.”。雙及物動詞可以用另一個特徵來描述。
下面是英語動詞子類別的示例表格,以及它們的匹配特徵和示例
| 子類別 | 示例 |
|---|---|
| 不及物動詞:V[NP __] | Leave |
| 及物動詞型別 1:V[NP __ NP] | Hit |
| 及物動詞型別 2:V[NP __ {NP/CP}] | Ask |
| 雙及物動詞型別 1:V[NP __ NP NP] | Spare |
| 雙及物動詞型別 2:V[NP __ NP PP] | Put |
| 雙及物動詞型別 3:V[NP __ NP {NP/CP}] | Give |
| 雙及物動詞型別 4:V[NP __ NP {NP/PP/CP}] | Tell |
成分、樹形圖、規則
[edit | edit source]成分是句子中任何相互關聯形成一個單元的專案組。到目前為止,我們看到的唯一成分是單詞,但還有其他型別的成分,即短語。短語是彼此之間聯絡更緊密的單詞或短語組,而不是與組外單詞和短語聯絡更緊密。通常我們說每個短語都有一個核心(一個詞),每個核心都會生成一個短語,但並非總是如此。特定句法類別的核心會生成該類別的短語:名詞(N)會生成名詞短語(NP),動詞(V)會生成動詞短語(VP)等。我們也可以說短語可以由兩個相同型別的連線短語組成,而沒有核心。
我們可以透過詢問兩個詞是否比其他詞更緊密地相互關聯來檢視句子中的成分。例如,在“the dog bit the man”中,我們會說“the”和“dog”彼此構成一個成分,“the”和“man”構成一個成分,依此類推。知道形成了哪種短語取決於什麼對成分的含義更重要。“The dog”和“the man”更多地是關於“dog”和“man”,而不太是關於“the”,因此這兩個成分都將是 NP。
顯示句子的成分層次結構
[edit | edit source]方括號
[edit | edit source]顯示成分有兩種方法。第一種方法是使用方括號。這在文字中是最容易做到的,因為它不需要任何特殊的形狀或其他東西。顯示成分的通用方法是在成分周圍加上方括號,並在第一個方括號之後加上成分型別的下標。前一個示例句子中識別的兩個成分將是
- 1) [NP [D the] [N dog]]
- 2) [NP [D the] [N man]]
有時你會看到一些成分被不完全地括起來,例如
- 3) [NP the dog]
- 4) [NP the man]
當被忽略的結構與顯示成分所展示的內容無關時,就會發生這種情況。你可能還會看到沒有標籤的括號(例如 [the dog] 表示 [NP the dog]),當標籤與上下文無關或可以從上下文中恢復時。當你從成分開始時,最好完全指示成分,無論其相關性如何。
樹形圖更常用於顯示句子的結構。在樹形圖中,成分由節點和連線線表示。連線線將一個成分連線到另一個包含它的成分。節點本身代表型別(N、NP、V、VP 等)。詞頭(N、V 等)通常在它們下面寫下實際的詞。[NP [D the] [N dog]] 和 [NP [D the] [N man]] 的樹形版本如下所示。
- 5 & 6)


 三角形用於表示成分未完全顯示。
- 7 & 8)
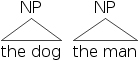

 繪製樹形結構的一個普遍規則是連線線永不交叉。換句話說,一個成分必須由相鄰的專案組成。在高階語法教程中,我們將探索如何處理非相鄰成分及其出現的原因。
透過括號和樹形圖顯示成分有助於描述特定句子的結構,但語法是關於描述所有句子的結構以及這些句子遵循的規則。因此,我們需要一種方法來描述哪些成分是可接受的,以及它們包含的內容。觀察簡單的例子“the dog”和“the man”,我們可以推匯出英語 NP 的一些基本規則。在每個例子中,我們都有一個限定詞後跟一個名詞。如果我們將它們顛倒過來,得到“dog the”和“man the”,就會得到不語法短語,所以我們可以說 NP 由 D 後跟 N 組成。我們可以更簡潔地表示為
- 9) NP → D N
當然,英語也允許在名詞之前、限定詞之後出現形容詞短語 AdjP,例如“the big dog”(但不能像“big the dog”或“the dog big”那樣),以及在名詞之後出現介詞短語 PP,例如“the dog in the house”(但不能像“in the house the dog”或“the in the house dog”那樣)。因此,英語 NP 可以更完整地描述如下
- 10) NP → D AdjP N PP
我們可以使用 X、Y、Z 等作為元變數,表示任意詞頭型別。如果某項是可選的,我們將其放在括號內,例如 (XP)。交替選擇放在花括號內並用斜槓分隔,例如 {XP/YP}。如果您需要任何數量的某項,例如“XP 或 XP XP 或 XP XP XP 或...” ,您可以將其中一項加上一個“+”,例如 XP+。這些可以組合起來建立多個可選專案——(XP+) 表示沒有 XP、一個 XP、兩個 XP 等——或多個專案的例項——{XP/YP/ZP}+ 表示一個或多個短語,每個短語可以是 XP、YP 或 ZP——等等。
這些規則,左側是短語,右側是該短語的內容,稱為短語結構規則或 PS 規則。對於英語,我們可以用以下 PS 規則集來描述大量的句子
- 11) CP → (C) TP
- 12) TP → {NP/CP} (T) VP
- 13) VP → (AdvP+) V (NP) ({NP/CP}) (AdvP+) (PP+) (AdvP+)
- 14) NP → (D) (AdjP+) N (PP+) (CP)
- 15) PP → P (NP)
- 16) AdjP → (AdvP) Adj
- 17) AdvP → (AdvP) Adv
- 18) XP → XP conj XP
- 19) X → X conj X
因此,如果我們想描述句子“the dog bit the man”,我們可以用這個帶括號的句子
- 20) [TP [NP [D the] [N dog]] [VP [V bit] [NP [D the] [N man]]]]
以及樹形圖
- 21)
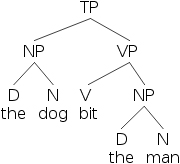


要為一種語言制定 PS 規則列表,有必要確定哪些形式構成成分。在某種程度上,我們可以透過直覺來判斷母語的成分,但在很多情況下,很難判斷什麼是成分,什麼不是成分。為了更容易確定成分,有許多測試可以在任何潛在的成分上執行。在高階語法教程中,我們將看到這些測試如何讓我們有理由修改 PS 規則,並將它們重新表述為一個全新的理論。
測試成分的一種方法是看潛在的成分是否可以被單個詞替換,而不影響句子的含義。
- 22a) The dog bit the man.
- 22b) The dog bit him.
- 23a) The dog bit the man.
- 23b) It bit him.
在這些例子中,我們看到代詞替換了 D N 形式的詞串,這表明 D N 形成一個成分。這當然是一個英語 NP。然後我們可以說,任何可以被代詞替換的東西都是相同型別的成分,這讓我們可以取任何句子集合,並識別代詞可替換成分的例子,從而識別可以進入這些成分的東西。這就是我們獲得構成 NP 規則的原因。
另一種成分測試是獨立存在測試(也稱為句子片段測試)。例如,如果一組詞可以用作問題的答案,也就是說,如果它可以作為有意義的獨立子句獨立存在,那麼我們可以說它是一個成分。
- 24a) The dog bit the man.
- 24b) The dog bit the man.
- What did the dog do?
- 25a) Bit the man.
- 25b) *Bit the.
這些表明“bit the man”形成了一些成分,而“bit the”在英語中不形成成分。* 透過繼續對 V 的測試,我們找到了 VP 的定義。
* 在“the”和“him/her”形式相同的語言中,情況就不那麼清楚了。例如,西班牙語的la "her"類似於la "the (feminine singular)"。
移動測試透過移動潛在的成分而不使句子變得不語法來顯示成分。分裂式句子涉及在潛在成分之前插入 It is 或 It was,並在之後插入 that (26)。前置/偽分裂式句子涉及插入 Is/are what/who 以及潛在成分 (27)。將句子變成被動語態,交換主語和賓語,在前主語之前插入 by,並將動詞變成被動語態(bit 變成 was bitten 等),也將表明成分。
- 26) It was the dog that bit the man.
- 27) The dog is what bit the man.
- 28) The man was bitten by the dog.
最後一種成分測試涉及取一個潛在的成分,並將其與另一個類似的東西連線起來。
- 29) The dog bit the man.
- 30) The dog and the cat bit the man.
成分測試並不總是保證。在某些情況下,一種語言似乎存在違反其他先前確定的成分的成分。
- 31) The cat saw and the dog bit the man.
(31) 會告訴我們“the cat saw”和“the dog bit”分別形成一個成分,因為它們似乎滿足連線測試,這違反了先前確定的成分規則。這種情況需要進一步調查。解決這個問題的一種方法是在原則和引數框架中假設“the cat saw and the dog bit”實際上並不是成分,而是存在一個未說出口的代詞(即,它具有詞彙內容,但沒有語音內容),稱為 pro,它指的是“the man”。這將使我們能夠將 (31) 重新分析為兩個完整句子的連線。
- 32) [The cat saw [pro]i] and [the dog bit [the man]i]
這裡下標“i”用於表示 pro 和 the man 引用的是同一個東西。在這個分析中,我們之前為英語找到的 PS 規則沒有被違反。其他框架將以不同的方式處理這種情況。例如,詞彙功能語法不使用 pro,而是允許更寬鬆的成分種類。這種測試失敗表明句子中存在比表面上看起來更多的東西,我們在高階教程中將探索解決這些明顯奇異的不同方法。
如前所述,樹形結構具有不同的組成部分,即節點,它們包含或被其他節點包含。這種包含和共包含的層次結構使我們能夠識別節點之間的一些關係,這些關係在描述語言中事物為什麼表現為特定行為方面很有用。
從一些簡單的 PS 規則開始
- 1) A → B C
- 2) B → D E
- 3) C → F G
- 4) F → H
我們可以生成一棵樹
- 5)


 現在我們可以探索樹形圖的不同部分。A、B、... 是節點的示例。節點透過連線線連線在一起,這些連線線區分出不同的分支。B 及其下面的節點構成一個分支,與 C 及其下面的節點不同。D 是一個與 E 不同的分支,等等。如果一個節點下面只有一個分支,則稱為非分支節點;如果它下面有多個分支,則稱為分支節點。
- 6)

- 7)
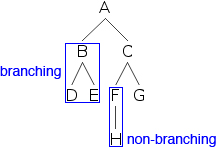


 在樹的頂端,我們找到了 A,它不在任何其他節點的下方。這樣的節點稱為根節點。在底部,我們找到了 D、E、H 和 G,它們下方沒有節點。這樣的節點稱為終端節點(有時也稱為葉節點)。節點 A、B、C 和 F 都有節點在它們下方,被稱為非終端節點。賦予節點的實際字母稱為標籤。
終端節點幾乎總是詞頭(在高階語法教程中,我們將說所有終端節點也都是詞頭),所有非終端節點都是短語。
節點之間最簡單的結構關係是支配關係。如果一個節點在樹中位於另一個節點的上方,則該節點支配另一個節點。在示例樹中,A 支配所有其他節點,B 支配 D 和 E,C 支配 F、H 和 G,F 支配 H。
- 8) 當且僅當 X 在樹中比 Y 高(即 X 和根節點之間有更少的節點)並且您可以透過僅從 Y 向上到 X 或僅從 X 向下到 Y 來跟蹤 X 和 Y 之間的路徑時,節點 X 支配另一個節點 Y。
我們還可以說明哪些終端節點集合被哪些其他節點支配。例如,集合 {D, E} 被 B 和 A 都支配。對於 B,該集合與被 B 支配的節點集合相同,但對於 A,該集合僅是部分被 A 支配的節點。然後我們可以說 B 完全支配該集合,而 A 則不完全支配該集合。
- 9) 當且僅當 X 支配集合中的所有成員,並且所有被 X 支配的終端節點都是集合的成員時,節點 X 完全支配終端節點集合 {Y, ..., Z}。
- 10)


 我們還可以注意到節點在支配關係中彼此之間的距離關係。一些節點,例如 F,直接位於其他節點的上方,在本例中為 H,而其他支配節點,例如 A,則沒有直接位於上方。當一個節點直接位於另一個節點的上方時,它直接支配該節點。
- 11) 當且僅當 X 支配 Z 並且沒有節點 Y 支配 Z 並且本身被 X 支配時,節點 X 直接支配節點 Z。
- 12)


直接支配另一個節點的節點被稱為該另一個節點的母節點。被另一個節點直接支配的節點被稱為該另一個節點的子節點。同一個節點的子節點被稱為姐妹節點。
另一種可以用支配關係來描述的簡單關係是成分性。
- 13) 當且僅當 Y 支配 X 時,節點 X 是節點 Y 的一個成分。
- 14)


優先關係不像支配關係那麼簡單,但仍然相當簡單。如果一個節點出現在另一個節點之前,則該節點優先於另一個節點。但優先關係有兩種截然不同的型別,其中一種型別依賴於另一種型別。
- 15) 當且僅當 X 和 Y 都被同一個節點直接支配,並且 X 出現在 Y 的左側時,節點 X 姐妹優先於節點 Y。
- 16)



- 17) 當且僅當兩個節點都不支配另一個節點,並且 X 或支配 X 的節點姐妹優先於 Y 或支配 Y 的節點時,節點 X 優先於節點 Y。
- 18)


優先關係的直接性在分析直接賓語和間接賓語等方面可以發揮重要作用。優先關係中的直接性與支配關係中的直接性類似,因此定義將類似。
- 19) 當且僅當 X 優先於 Z 並且沒有節點 Y 優先於 Z 並且本身被 X 優先時,節點 X 直接優先於節點 Z。
- 20)


C-支配可能是構建語言語法工作理論時最實用的結構關係。如果您理解支配和姐妹關係,那麼 C-支配關係應該很容易理解。基本上,如果一個節點是另一個節點的姐妹節點,或者是一個支配該節點的節點的姐妹節點,則該節點 C-支配另一個節點。
- 21) 當且僅當直接支配 X 的節點也支配 Y 時,節點 X C-支配節點 Y。
您可以透過遵循一個簡單的規則來找到被 C-支配的節點:向上走一步,然後向下走一步或多步,您所到達的任何節點都將被您開始的節點 C-支配。
- 22)


C-支配關係也可能表現出對稱性。對稱性在某些成分的行為中可以發揮重要作用。對稱 C-支配本質上是姐妹關係。不對稱 C-支配本質上是所有其他 C-支配情況。
- 23) 當且僅當 X C-支配 Y 並且 Y C-支配 X 時,節點 X 對稱 C-支配節點 Y。
- 24) 當且僅當 X C-支配 Y 並且 Y 不 C-支配 X 時,節點 X 不對稱 C-支配節點 Y。
- 25)



支配是另一種重要的關係。它建立在 C-支配之上,因此很容易用 C-支配來定義。它看起來非常類似於直接性關係。
- 26) 當且僅當 X C-支配 Z 並且沒有節點 Y C-支配 Z 並且本身被 X C-支配時,節點 X 支配節點 Z。
- 27)


有些支配關係只適用於詞頭之間或短語之間。我們可以根據參與節點的型別定義支配關係的兩種子型別。
- 28) 當且僅當 X C-支配 Z,沒有節點 Y C-支配 Z 並且本身被 X C-支配,並且 X、Y 和 Z 都是詞頭/終端節點時,節點 X 詞頭支配節點 Z。
- 29) 當且僅當 Z C-支配 X,沒有節點 Y C-支配 Z 並且本身被 X C-支配,並且 X、Y 和 Z 都是短語/非終端節點時,節點 X 短語支配節點 Z。
- 30)

- 31)

最後一種關係是語法關係。這些根本不是結構關係,而是語義關係,這些關係往往在語言中以相同的結構形式結束。在高階語法教程中,其中一些將被修改。
這些關係完全取決於語言的 PS 規則,在本例中為英語。
- 32) 主語 (S):TP 的 NP 或 CP 子節點。
- 33) (直接)賓語 (O 或 DO):由及物動詞引導的 VP 的 NP 或 CP 子節點。
- 34) 介詞賓語:PP 的 NP 或 CP 子節點。
- 35)


 英語有一種型別的賓語,稱為間接賓語 (IO)。間接賓語有時可以像普通的賓語一樣出現,有時可以像介詞賓語一樣出現。
- 36)

- 37)



 現在,我們有了兩種型別的賓語,它們都可能成為 VP 的 NP 子節點,我們需要重新定義“直接賓語”一詞,並定義“間接賓語”。
- 38) 直接賓語 (v2)
- a) VP 的 NP 或 CP 子節點,帶有 V[NP __ NP]、V[NP __ CP]、V[NP __ {NP/CP}] 和 V[NP __ NP PP]
- b) VP 的 NP 或 CP 子節點,被 NP 或 PP 姐妹優先,帶有 V[NP __ {NP/PP} {NP/CP}]
- 39) 間接賓語
- a) VP 的 PP 子節點,緊接在 VP 的 NP 子節點之前,帶有 V[NP __ NP PP]
- b) VP 的 NP 子節點,緊接在 V 之前,帶有 V[NP __ NP {NP/CP}]
還有一種型別的賓語,斜賓語,通常用介詞標記,如
- 40) 我吃 [PP 帶果醬] 的吐司。
斜賓語可以出現在與間接賓語相同的位置,有時也可以出現在直接賓語的位置。斜賓語與其他型別賓語的區別在於它是否出現在動詞的論元特徵中。例如,動詞“eat”具有論元特徵 [NP __ NP]。如果一個 PP(例如“with jam”)出現在句子中,那麼它一定是一個斜賓語,因為它沒有在論元特徵中指示。
綁定理論試圖透過我們迄今為止建立的結構框架來解釋涉及代詞和反身代詞的某些現象。要理解這個理論的由來,首先要理解這些詞的特殊之處,以及它們如何區別於普通名詞。
普通名詞被稱為R-表示式(“r”代表“引用”)。它們的意義源於它們對句子之外的事物的引用,即世界上的事物(例如,“樹”,“汽車”)。另一方面,代詞的意義源於對句子中其他詞的引用(對R-表示式),或者來自語境等(例如,“他”,“她”,“他們”)。最後,反身代詞的意義只能來自句子中的R-表示式(例如,“它自己”,“我們自己”)。
我們可以在這些語法錯誤的句子中找到代詞和反身代詞特殊行為的例子
- 1) *它自己咬了狗。
- 2) *他看到了約翰。(其中“他”指的是約翰)
所以問題是為什麼這些句子語法錯誤,為了找出原因,我們需要確定在語法正確的例子和語法錯誤的例子之間有什麼區別。
首先要介紹一種方法來指示兩個短語是否指代世界上的同一實體。我們將透過在每個唯一實體的詞或短語之後使用唯一的下標字母來實現這一點。
- 3) [狗]i 咬了 [人]j。
- 4) [鮑勃]i 給 [瑪麗亞]j [書]k。
- 5) [約翰]i 認為 [他]j 喜歡 [蘋果派]k。
- 6) [弗朗辛]i 在 [鏡子]j 中看到了 [她自己]i。
這種索引允許我們透過識別每個短語上的相同下標來記錄何時兩個短語指代同一個實體。透過擁有相同的索引,也就是說,透過共指,我們可以確定它們共指同一個實體。
其次,需要一個簡單的賦予意義的概念。如果一個短語賦予另一個短語意義,我們將稱之為先行詞。
現在我們可以探索一些語法正確和語法錯誤的句子,找出一些初始的相似點和差異。
- 7) 約翰i 在鏡子裡看到了自己i。
- 8) [約翰i 的狗]j 在鏡子裡看到了自己j。
- 9) *[約翰i 的狗]j 在鏡子裡看到了自己i。
透過檢查結構,我們發現反身代詞自己不能與包含在另一個位於主語位置的短語中的R-表示式共指。如果我們檢查下面的樹形圖,我們會發現,在語法正確的例子中,先行詞總是c-支配反身代詞。
- 10)
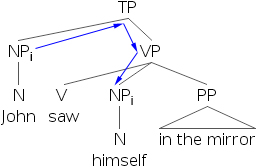
- 11)
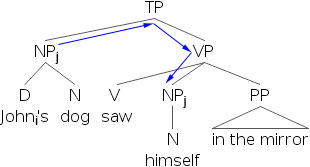
- 12)




 現在我們可以定義繫結
- 13) 當且僅當X c-支配Y,並且X和Y共指時,節點X繫結節點Y。
在7-9中,只有當反身代詞被先行詞繫結時,句子才是語法正確的。如果這是普遍的,那麼我們應該找到反身代詞繫結先行詞的語法錯誤的情況。
- 14)


 由於這些都是語法錯誤,讓我們用這條規則來解釋。
- 15) 原則A:反身代詞必須被其先行詞繫結。
如果英語像那樣簡單,我們就完成了繫結的學習,但不幸的是,英語並沒有那麼簡單。我們可以很容易地找到一些例子,其中反身代詞被其先行詞繫結,但句子仍然是語法錯誤的。
- 16)
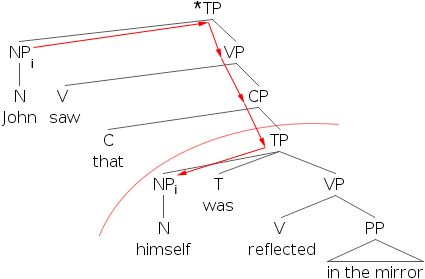

 為了解釋這一點,我們必須引入繫結域的概念。簡單來說,繫結域是包含反身代詞的從句(TP)。現在,我們注意到(16)中,先行詞位於反身代詞繫結域之外。我們可以修改原則A,使其包含一個區域性性約束(一條涉及接近度的規則)。
- 17) 原則A(v.2):反身代詞必須在其繫結域內被其先行詞繫結。
現在,這個理論就足夠了,但在高階語法教程中,我們將研究一些在繫結域內但仍然是語法錯誤的容易找到的繫結例子,並且我們將看到如何修改我們的理論使其更適合。
代詞的行為恰好與反身代詞相反。考慮以下句子
- 18) 約翰i 在鏡子裡看到了他j。
- 19) *約翰i 在鏡子裡看到了他i。
- 20) 約翰i 看到他i 反映在鏡子裡。
- 21) 約翰i 看到他j 反映在鏡子裡。
- 22)
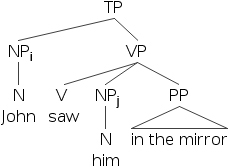
- 23)

- 24)

- 25)





 在(18)中,代詞是未繫結的(或自由的),但在(19)中,代詞是繫結的。觀察嵌入從句,我們發現,如果代詞位於嵌入從句中,即不同的繫結域,那麼無論共指與否,句子都是語法正確的。在語法正確的例子中,代詞在其繫結域內是自由的,而在語法錯誤的例子中,它是繫結的。我們可以從這一點中得出第二條規則。
- 26) 原則B:代詞必須在其繫結域內是自由的。
在反身代詞和代詞之後,最後要處理的是R-表示式,即所有不是反身代詞和代詞的名詞和短語。起初,鑑於我們之前的規則,我們似乎不需要描述它們可以放置的位置,但是我們可以找到完全是語法錯誤的句子,它們並沒有違反原則A或B。
- 27) *他i 咬了費多i。
- 28) *鮑勃i 看到了弗蘭克i。
- 29) 他i 咬了費多j。
- 30) 鮑勃i 看到了弗蘭克j。
- 31)
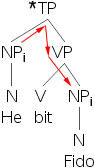
- 32)

- 33)

- 34)





 在這些情況下,我們注意到,只有當R-表示式被繫結時,句子才是語法錯誤的。現在,我們可以得出第三條規則。
- 35) 原則C:R-表示式必須是自由的。
有了繫結,我們現在擁有一個相當完整的工具來描述語言的許多行為,包括結構方面的行為,並且我們可以開始研究使用這些知識可以做些什麼。
現代語言學最關心的問題之一是發現所有人類語言的根本原則。正如我們在高階語法教程中將看到的那樣,這將是進一步發展我們已經討論的理論的動力。但即使在我們目前工作的水平上,我們也可以探索自然語言中的一些趨勢,這些趨勢讓我們洞悉了從認知過程如何形成句子到語法特徵如何隨時間發展等問題。
這些趨勢被稱為語言普遍性或語法普遍性,它們分為兩種型別:純粹的統計趨勢,以及真正的普遍性(或“蘊含普遍性”)。統計趨勢就是統計趨勢——在模式中出現的趨勢,很可能是在受認知便利性等多種力量影響下,通過歷史變化而產生的。另一方面,蘊含普遍性往往得到更加嚴格的遵循,並做出預測性陳述,即如果一種語言具有特徵X,那麼它幾乎肯定會也具有特徵Y。還有其他方法來劃分普遍性,例如,它們影響的語言部分。語音/音韻普遍性涉及語言所經歷的聲音和聲音變化,形態普遍性涉及詞語結構和語素,等等。在本節中,我將介紹與語法相關的普遍性,並探討這些普遍性可能如何從語法中產生。
詞序型別學是根據語言中某些型別的詞語在句子或成分中相對於彼此的順序來對語言進行分類。最常見的詞序型別學分類是句子中主語、賓語和動詞的順序。由於有三種類型的詞語,因此我們有六種可能的配置:VSO、SVO、SOV、VOS、OVS、OSV。在對自然語言的調查中,前三種(主語位於賓語之前)絕大多數被用作正常的陳述句詞序,後三種佔較低的個位數百分比。我們將這兩種詞序分別稱為 SO 和 OS。對於每種詞序,我們還將根據動詞的位置來標識它們,分別用 I、II 和 III 表示動詞位於句首、句中和句尾。然後可以透過兩種組合來對語言進行分類,例如 SO/I、OS/III 等。由於 SO 詞序非常普遍,因此 SO 詞序可以簡單地根據動詞位置數字來推斷(例如 III 表示 SO/III 而不是 OS/III 等)。
對語言進行分類的第二種方法是根據其使用介詞或後置詞,我們分別稱之為 Pr 和 Po。第三種是形容詞和名詞的順序;如果名詞在其形容詞之前,我們可以稱之為 N,如果名詞在其形容詞之後,我們可以稱之為 A。檢視 Pr/Po 和 A/N 分類與 I/II/III 分類之間的關係,我們可以發現一些有趣的趨勢,例如 I 型語言總是也是 Pr,III 型語言通常是 Po 等等。現在我們可以列出可能的配置(忽略罕見的 OS 配置)並檢視它們的頻率。
- I-PR-A:罕見
- I-PR-N:常見
- I-PO-A:罕見
- I-PO-N:罕見
- II-PR-A:常見
- II-PR-N:更常見
- II-PO-A:罕見
- II-PO-N:不太罕見
- III-PR-A:罕見
- III-PR-N:罕見
- III-PO-A:更常見
- III-PO-N:常見
僅從這些資料和我們之前對語法的瞭解,我們發現了一個趨勢,這對構建可信的語言很有幫助。常見的形式 I-PR-N、II-PR 和 III-PO 與其他形式或子形式相比,都顯示出對保持一致的頭部位置的偏好,即語言更傾向於儘可能地保持頭部位於句首或句尾。
句法普遍性比典型的詞序普遍性更具體。它們仍然在句子的詞序中可見,但它們的範圍往往更專業。例如,在是非問句中,疑問詞傾向於出現在它們所標記的詞語之後,並且它們傾向於更多地出現在 II 型和 III 型語言中;當它們出現在 I 型語言中時,疑問詞出現在它們所標記的詞語之前。助動詞也表現出有趣的句法模式,這種模式遵循關於一致頭部位置的概括。
形態句法普遍性介於句法普遍性和形態普遍性之間,因為它們涉及與句法特徵相關的形態學趨勢。例如,我們發現形態學專案傾向於表現得與 PP 中的頭部相似,即如果一種語言只有字尾,那麼它應該表現得像使用後置詞的語言,並且是 III 型,實際上也確實如此。實際上,如果一種語言只有字尾,那麼它就有後置詞,如果它只有字首,那麼它就有介詞。
在名詞和形容詞一致的情況下,N 語言總是具有一致的形容詞。更一般地,III 型語言幾乎總是具有格系統。與語言之間語法相關趨勢的全部複雜性超出了本節的範圍,但您可以在此處閱讀更多相關資訊。我們可以從這些普遍性中推匯出的一些含義將構成一套很好的語法規則。例如,詞綴表現得像介詞的趨勢可能表明一些隱藏的結構,這些結構將詞綴作為一些介詞狀短語的頭部,經歷了從介詞到詞綴的歷史變化,從而使我們瞭解瞭如何使構造語言演變。語言試圖在頭部位置上保持一致的趨勢可能是由於一個歷史過程,該過程將詞類相互轉變。或者,為了使語言真正具有外星感,可以顛倒這些普遍性,從而使 Po 成為 I 型語言或類似的東西。瞭解普遍性顯然可以更容易地創造出自然主義語言和有趣的外星語言。
格林伯格,約瑟夫。“語法的一些普遍性”。1999 年。2007 年 12 月 10 日 <https://web.archive.org/web/20100531044540/http://angli02.kgw.tu-berlin.de/Korean/Artikel02/>。
到目前為止,我們已經探索了語法作為一組形式理論的開端,但本教程旨在幫助構建語言。為了瞭解如何使用這些知識,我將從兩個角度來探討構建語言的過程。第一個是從頭開始構建,沒有任何關於語言語法應該是什麼樣的先入為主的想法。然後,我將探討如何將一些模糊的想法擴充套件成完整的語言,並期待這些系統出現在其中,在此過程中,我將探討如何使用相同的工具來規範現有語言。
從頭開始設計語法在理論上是一個簡單的過程。在沒有任何關於某些特徵應該是什麼樣的先入為主的想法的情況下,我們可以遵循一個有序的方法來進行這個過程。實際上,這個過程是如此公式化,以至於即使是列出要為語言定義的事項列表也可能有用。
- 1:頭部位於句首還是句尾
- 2:頭部和短語(即,語言有 Ns 嗎?NPs 嗎?Vs 嗎?VPs 嗎?等等)
- 3:與 (1) 不同的短語或具有例外替代形式的短語
- 4:PS 規則
在 (2) 和 (4) 中要牢記的是,結構不必與英語完全相同。現代理論傾向於嘗試用相同的基本公式來描述每種語言,相同之處越多越好,但這並不意味著您的語言必須如此。如果您想將主語放到 VP 中,並將賓語從 VP 中移出,當然可以這樣做。但請記住,制定截然不同的規則意味著您的成分測試應該具有等效的形式。如果您確實將主語移入 VP,並將賓語移出,那麼您將需要一種情況,您可以在其中用一個替代詞(類似於“do so”)替換 VP,並且具有相同含義。重要的是要牢記我們為什麼說語言具有我們為它們發現的規則,或者如前所述,是我們開發的規則。
為預先存在的思想尋找語法比從頭開始設計語法要複雜一些。因為我們已經有一些“規範”形式,所以我們必須對它們進行測試以發現它們的行為方式。也許我們可以列出一些要在這裡做的事情來識別語言的特徵。
- 1:成分測試以確定構成結構的內容及其方式
- 2:PS 規則以描述結構
- 3:結構的頭部位置是典型的還是例外?
- 4a:1-3 的概括作為從頭開始設計語法的步驟指南
- 4b:建立更多想法並對其進行分析
擁有多個想法可以更容易地決定 (3)。例如,如果我們有三個想法最終具有相同的頭部位置,那麼我們可能想說我們的語言應該具有該位置作為典型位置。或者,如果這些想法具有不同的頭部位置,我們可以選擇我們更喜歡的那個並將其設為典型,而將另一個設為例外。
上面列出的規則同樣適用於描述過程,將整個語言視為一個需要分析的巨大想法。來自非正式語法的輸入可以加快建立正式語法的過程。
當前理論非常強大,可以解釋自然語言中的許多現象。儘管如此,它仍然錯過了大量至少在英語中是語法的句子,並且所給出的理論根本無法解釋某些語言。
我們目前的理論是以英語為基礎的,但英語本身存在一些明顯的反例。僅在名詞短語內部,我們就發現了低於 NP 但高於 N 的成分結構示例。例如,“the big brown dog and the little one too”。在這個例子中,“one” 替換了 “brown dog”,表明 “brown dog” 本身就是一個成分,但根據我們現有的英語 PS 規則,這種情況是不可能出現的。因此,我們遇到了一個異常成分。
- [NP [D the] [AdjP big] [?? [AdjP brown] [N dog]]].
愛爾蘭語
[edit | edit source]愛爾蘭語屬於 SO-I 語言型別,這意味著它採用 VSO 詞序。使用上述語法,將主語作為 TP 的子節點會導致它無法出現在動詞和賓語之間。如果我們在 V 和 VP 之間建立新的結構,就像我們對英語提出的建議那樣,我們仍然會發現一些不符合詞序的例句。例如,愛爾蘭語在使用助動詞時採用 AuxSVO 詞序,這使得很難用一個規則來解釋詞序。
日語和拉丁語
[edit | edit source]日語和拉丁語有時被稱為非配置語言,這意味著它們在句法層面上沒有顯著的詞序。例如,日語只要求動詞出現在句末(日語屬於 III 類語言),以及動詞補語出現在動詞之前。拉丁語通常被認為是一個在句法層面上完全沒有詞序的語言。像這樣的非配置語言需要大量的 PS 規則,每種可能的詞序對應一條規則。對於長句來說,這很快就會變得難以駕馭。
在高階語法教程中,我們將瞭解現代語言學如何處理這些問題,並探索一些描述語言行為的實驗方法,這些方法在虛構語言的構建過程中更有用。