命題邏輯
命題邏輯試圖捕捉自然語言的某些邏輯特徵。特別是,它涵蓋了句子的真值函式連線。它的形式語言專門識別命題連線
- 並非_____
- _____ 和 _____
- _____ 或 _____
- _____ 或 _____ (或兩者)
- 如果 _____, 則 _____
- _____ 當且僅當 _____
空白處應填入可以為真或假的語句。例如,“今天正在下雨”或“明天會下雪”。最終的句子是否為真,完全取決於填入的語句是否為真。例如,如果今天正在下雨,但明天不會下雪,那麼說“今天正在下雨或者明天會下雪”是正確的。另一方面,說“今天正在下雨並且明天會下雪”是錯誤的,因為明天不會下雪。
“一個語句是否為真”在邏輯學行話中被稱為真值。因此,“今天正在下雨或者今天沒有下雨”的真值為真,而“今天正在下雨並且今天沒有下雨”的真值為假。
請注意,上面列出的命題連線並不包括所有可能的真值組合。例如,沒有一個連線在兩個子語句都為真,兩個子語句都為假,或第一個子語句為真而另一個子語句為假時為真,而在其他情況下為假。但是,您可以將上面的連線組合在一起,以構建任何數量的子語句的任何真值組合。
我們已經預設地採取了持續爭論中的一個立場。上面看似簡單的開頭已經提出了一些問題,列舉如下。
- 我們是否應該只承認真或假的句子進入我們的邏輯?多值邏輯允許更大範圍的句子。
- 上面列出的連線真的是真值函式嗎?我們是否應該承認非真值函式句子進入我們的邏輯?
- 邏輯應該以什麼作為它的真值承擔者(為真或假的事物)?今天領先的兩個競爭者是句子和命題。
- 句子。它們由一系列單詞和可能的標點符號組成。句子“貓在墊子上”包含六個元素:“the”、“cat”、“is”、“on”、“the”和“mat”。
- 命題。它們是句子的意思。它們是句子表達的內容,或者某人在說句子時表達的內容。命題貓在墊子上包含三個元素:一隻貓、一個墊子和“在”關係。
- 在華夏公益教科書和維基百科的別處,您將看到“命題邏輯”(或更確切地說是“命題演算”,見下文)的名稱,以及對命題的處理比看到“命題邏輯”的名稱和對句子的處理更為常見。我們在這裡的選擇代表了貢獻者的觀點,即哪種立場在當代邏輯學家中更流行,以及您在該主題的標準教科書中最有可能看到什麼。關於流行觀點是否真正正確的考慮因素在這裡沒有討論。
- 一些作者會使用“語句”來代替“句子”。您可能遇到的多數(但並非全部)此類作者將語句視為句子的一個子集,即那些要麼為真要麼為假的句子。這種“語句”的用法並不代表爭議中的第三個立場,而是將這些作者置於句子陣營。(然而,其他——特別是較老的——“語句”的用法可能將它們的作者置於第三個陣營。)
有時您會看到“演算”而不是“邏輯”,例如“命題演算”或“命題演算”,而不是“命題邏輯”或“命題邏輯”。雖然“命題”和“命題”之間的選擇是實質性的和哲學性的,但“邏輯”和“演算”之間的選擇僅僅是風格上的。
本頁非正式地描述了我們的命題語言,我們將其命名為 。將在形式語法和形式語義學中給出更正式的描述。
。將在形式語法和形式語義學中給出更正式的描述。
中的句子表示為句子字母,它們是單個字母,例如 等等。有些文字將它們限制為小寫字母,另一些文字將它們限制為大寫字母。我們將使用大寫字母。
等等。有些文字將它們限制為小寫字母,另一些文字將它們限制為大寫字母。我們將使用大寫字母。
直觀地,我們可以將語句字母視為英語句子,它們要麼為真,要麼為假。因此, 可以翻譯為“地球是一顆行星”(這是真的),或者“月亮是由綠色乳酪製成的”(這是假的)。但 不能翻譯為“偉大的想法瘋狂地沉睡著”,因為這樣的句子既不是真的也不是假的。英語和 之間的翻譯效果最好是限制在永恆的真假現在時句子,以陳述語氣表達。你會在下面的翻譯部分看到,我們並不總是遵循該建議,其中我們展示了一些句子,其真假並非永恆的。
可以翻譯為“地球是一顆行星”(這是真的),或者“月亮是由綠色乳酪製成的”(這是假的)。但 不能翻譯為“偉大的想法瘋狂地沉睡著”,因為這樣的句子既不是真的也不是假的。英語和 之間的翻譯效果最好是限制在永恆的真假現在時句子,以陳述語氣表達。你會在下面的翻譯部分看到,我們並不總是遵循該建議,其中我們展示了一些句子,其真假並非永恆的。
語句連線詞是命題邏輯中表示真值函式關係的特殊符號。它們用來從較小的句子構建較大的句子。然後,可以根據較小句子的真假來計算較大的句子的真假。

- 翻譯成英語為“和”。
 被稱為合取式,而 和
被稱為合取式,而 和  是它的合取項。
是它的合取項。- 為真,當且僅當 和 都為真,否則為假。
- 一些作者使用&(和號)、•(實心圓點)或並置。在最後一種情況下,作者會寫

- 而不是我們的


- 翻譯成英語為“或”。
 被稱為析取式,而 和 是它的析取項。
被稱為析取式,而 和 是它的析取項。- 為真,當且僅當 或 中至少有一個為真;否則為假。
- 有些作者可能會使用豎線:|。然而,這來自於計算機語言,而不是邏輯學家們的用法。邏輯學家通常將豎線保留用於與非(替代否定)。當用作與非時,它被稱為 Sheffer 豎線。

- 翻譯成英文為 'it is not the case that',但通常讀作 'not'。
 被稱為否定。
被稱為否定。- 為真,當且僅當 為假;否則為假。
- 有些作者使用~(波浪號)或−。有些作者使用上劃線,例如寫

- 而不是


- 翻譯成英文為 'if...then',但通常讀作 'arrow'。
 被稱為條件句。它的前件是 ,它的後件是 .
被稱為條件句。它的前件是 ,它的後件是 .- 為假,如果 為真,而 為假——否則為真。
- 根據定義, 等效於

- 有些作者使用 ⊃(鉤號)。

- 翻譯成英文是“當且僅當”。
 被稱為*雙條件式*。
被稱為*雙條件式*。- 為真,如果 和 都為真或都為假——否則為假。
- 根據定義, 等效於更冗長的
 。它也等效於
。它也等效於  ,兩個條件式的合取,其中第二個條件式的先行式和後件式與第一個條件式相反。
,兩個條件式的合取,其中第二個條件式的先行式和後件式與第一個條件式相反。
- 有些作者使用 ≡。
圓括號  和
和  用於分組。因此
用於分組。因此


是兩個不同且獨立的句子。每個否定、合取、析取、條件和雙條件都只有一個括號對。
(1) 一個原子句是一個僅包含單個句子字母的句子。一個分子句是一個至少包含一個句子連線詞的句子。主連線詞是指控制整個句子的連線詞。原子句當然沒有主連線詞。
(2) 條件和雙條件的⊃ 和≡ 符號在歷史上更為古老,也許更傳統,在華夏公益教科書 和 維基百科 上比我們箭頭和雙箭頭更常見。它們起源於阿爾弗雷德·諾思·懷特黑德 和 伯特蘭·羅素 在《數學原理》 中。我們箭頭和雙箭頭似乎起源於 阿爾弗雷德·塔爾斯基,並且可能比懷特黑德和羅素的⊃ 和≡ 今天更流行。
(3) 有時你會看到人們將我們的箭頭讀作蘊含。這在華夏公益教科書 和 維基百科 中相當常見。但是,大多數邏輯學家更喜歡將“蘊含”保留用於元語言使用。他們會說
- 如果 P 那麼 Q
或者甚至
- P 箭頭 Q
他們贊成
- 'P' 蘊含 'Q'
但會反對
- P 蘊含 Q
考慮以下英語句子
- 如果下雨而且瓊斯出去散步,那麼瓊斯帶了雨傘。
- 如果是星期二或者星期三,那麼瓊斯出去散步。
為了在 中表達這些,我們首先為一些句子字母指定適當的英語翻譯。
 下雨了。
下雨了。 瓊斯出去散步。
瓊斯出去散步。 瓊斯帶了雨傘。
瓊斯帶了雨傘。 今天是星期二。
今天是星期二。 今天是星期三。
今天是星期三。
我們現在可以將我們的例子部分翻譯為


然後透過新增句子連線詞和括號完成翻譯

對於英語表示式,我們遵循使用單引號的邏輯傳統。這使我們能夠使用' 'It is raining' '作為'It is raining'的引用。
對於中的表示式,將它們視為自引用的更方便,因此引號是隱式的。因此,我們說上述示例將 (注意缺少引號)翻譯成'If it is Tuesday, then It is raining'。
(注意缺少引號)翻譯成'If it is Tuesday, then It is raining'。
在命題語言中,我們非正式地描述了我們的命題語言。在這裡,我們給出它的形式語法或文法。我們將我們的語言稱為。
- 句子字母:大寫字母'A' – 'Z',每個都有 (1) 上標 '0' 和 (2) 自然數下標。(自然數是正整數和零的集合。)因此,句子字母是



句子字母上的上標在我們進入謂詞邏輯之前並不重要,所以我們在這裡不必擔心它們。句子字母上的下標是為了確保無限供應的句子字母。在下一頁,我們將省略大多數上標和下標。
來自 詞彙的任何字元字串都是 的一個表示式。一些表示式在語法上是正確的。有些在 中與“Over talks David Mary the”在英語中的錯誤一樣。在 中,還有其他表示式與“jmr.ovn asgj as;lnre”在英語中的錯誤一樣糟糕。
我們稱 的語法上正確的表示式為良構式公式。當我們進入謂詞邏輯時,我們會發現只有部分良構式公式是句子。不過,目前,我們認為所有良構式公式都是句子。
的表示式被稱為 的良構式公式,如果它是根據以下規則構造的。
 該表示式包含單個句子字母
該表示式包含單個句子字母
 該表示式由其他良構式公式
該表示式由其他良構式公式 和
和 以以下方式之一構成
以以下方式之一構成





一般來說,我們將使用“公式”作為“良構公式”的簡寫。由於在 中的所有公式都是句子,我們將交替使用“公式”和“句子”。
我們將認為 的表示式是自引用的,因此將

看作包括隱含的引號。然而,像

需要特別考慮。它本身不是 的表達,因為 和 不在 的詞彙中。相反,它們在英語中用作變數,這些變數在 的表示式範圍內變化。這樣的變數被稱為 *元變數*,而使用 和元變數的詞彙的表示式被稱為 *元邏輯表示式*。假設我們讓 為  並且 為
並且 為  那麼 (1) 變成
那麼 (1) 變成
- '
 '
'  '
' '
'  '
' '
'
這與我們想要的並不一樣。相反,我們將 (1) 解釋為(使用明確的引號)
- 由 '' 後跟 後跟 '
 ' 後跟 後跟 '' 組成。
' 後跟 後跟 '' 組成。
遵循這種約定的顯式引號被稱為 *Quine 引號* 或 *角引號*。我們的角引號將是隱式的。
我們介紹(或在某些情況下重複)一些有用的句法術語。
- 我們區分表示式(或公式)和表示式的 *出現*(或公式)。公式

無論寫多少次都是同一個公式。然而,它包含句子字母 的三個出現和句子連線詞  的兩個出現。
的兩個出現。
- 是 的一個 子公式 當且僅當 和 都是公式,並且 包含 的一個出現。 是 的一個 真子公式 當且僅當 (i) 是 的子公式,並且 (ii) 與 不是同一個公式。
- 一個 原子公式 或者 原子句子 僅僅包含一個句子字母。或者換句話說,它是一個沒有句子連線詞的公式。一個 分子公式 或者 分子句子 包含至少一個句子連線詞的出現。
- 一個分子公式的 主連線詞 是在根據上述規則構建公式時新增的最後一個連線詞的出現。
- 一個 否定 是一個形如
 的公式,其中 是一個公式。
的公式,其中 是一個公式。
- 合取式是指形如
 的公式,其中 和 都是公式。在這種情況下, 和 都是合取項。
的公式,其中 和 都是公式。在這種情況下, 和 都是合取項。
- 析取式是指形如
 的公式,其中 和 都是公式。在這種情況下, 和 都是析取項。
的公式,其中 和 都是公式。在這種情況下, 和 都是析取項。
- 條件句 是一種形式為
 的公式,其中 和 都是公式。在這種情況下, 是前件,而 是後件。 的逆命題 是
的公式,其中 和 都是公式。在這種情況下, 是前件,而 是後件。 的逆命題 是  。 的逆否命題 是
。 的逆否命題 是  .
.
- 雙條件句 是一種形式為
 的公式,其中 和 都是公式。
的公式,其中 和 都是公式。

根據規則 (i),所有句子字母,包括

都是公式。然後,根據規則 (ii-a),否定

也是一個公式。然後根據規則 (ii-c) 和 (ii-b),我們得到析取和合取

作為公式。再次應用規則 (ii-a),我們得到否定

作為公式。最後,規則 (ii-c) 生成 (1) 的條件句,所以它也是一個公式。

這似乎是由規則 (ii-c) 從

其中第二個是根據規則 (i) 的公式。但第一個呢?它必須由規則 (ii-b) 從

但

不能透過規則 (ii-a) 生成。所以 (2) 不是公式。
在 命題語言 中,我們對命題語言給出了一個非正式的描述,即 。我們也已經給出了 的 形式語法。我們正式的語法生成大量的括號。這使得形式定義和其他規範更容易編寫,但也使語言使用起來相當笨拙。此外,所有下標和上標很快就會變得不必要地繁瑣。最終結果是一種醜陋且難以閱讀的語言。
我們將在指定形式時繼續使用正式語法。但是,我們將非正式地使用一個不太笨拙的變體用於其他目的。以下轉換規則將 的正式公式轉換為我們的非正式變體。
我們按照以下方式建立正式 公式的非正式變體。這些示例是累積的。
- 正式語法要求句子字母帶有上標“0”。在上標邏輯出現之前,上標並不是必需的,甚至沒有用,所以我們將在非正式變體中始終省略它們。例如,我們將寫
 而不是 。
而不是 。
- 如果下標是“0”,我們將省略它。因此,我們將寫 而不是 。但是,我們不能省略所有下標;我們仍然需要寫,例如,
 。
。
- 而不是

- 我們將讓一系列相同的二元連線符在右側關聯。例如,我們可以將正式的

- 轉換為非正式的

- 但是,對於以下情況,我們能做的最好的就是

- 是

- 我們將使用優先順序排序,儘可能省略內部括號。例如,我們將認為 的優先順序(範圍)低於 。這使我們能夠寫成

- 而不是

- 但是,我們無法從

- 中刪除內部括號。我們對這個公式的非正式變體是

- 完整的優先順序排序如下所示。
優先順序排序表示我們評估命題連線詞的順序。 的優先順序高於 。因此,在計算

的真值時,我們首先評估

首先。作用域是指由連線詞支配的表示式的長度。在(1)中, 的作用域比 的作用域更廣。因此,(1)中 支配整個句子,而(1)中 僅支配(1)中(2)的出現。
從最高優先順序(最窄作用域)到最低優先順序(最廣作用域)的完整排序如下所示:
| |
 |
|
最高優先順序(最窄作用域) |
| |
|
|
|
| |
|
|
|
| |
|
|
|
| |
 |
|
最低優先順序(最廣作用域) |
讓我們看一些例子。首先:

可以非正式地寫成

其次:

可以非正式地寫成

有些額外的括號可能對理解有幫助。在上例中,非正式的變體可能更容易閱讀,如

以及

注意非正式公式

恢復為官方形式

相反,非正式公式

恢復為官方形式

對於“狗叫”,英語語法指定它由一個複數名詞後跟一個不及物動片語成。英語語義學對“狗叫”的含義進行指定,即狗叫。
在命題語言中,我們對給出了一個非正式的描述。我們還給出了形式語法。然而,在這一點上,我們的語言只是一個玩具,一個我們可以像串珠一樣串起來的符號集合。我們確實有關於這些符號如何排序的規則。但在這一點上,這些規則也可能只是美學規則。良好格式的公式和格式錯誤的表達之間的區別,還沒有比漂亮和醜陋的項鍊之間的區別更重要。為了使我們的語言具有任何意義,能夠用於表達事物,我們需要一個形式語義。
任何給定的形式語言都可以與許多相互競爭的語義規則集中的任何一個配對。我們在這裡定義的語義是現代邏輯的常用語義。然而,人們已經提出了替代的語義規則集。的替代語義規則集包括(但當然不限於)直覺邏輯、相關邏輯、非單調邏輯和多值邏輯。
像這樣的形式語言的形式語義分為兩部分。
- 指定解釋的規則。一個解釋將語義值賦予形式語法的非邏輯符號。形式語言的語義將指定可以將哪些範圍的值賦予哪些類別的非邏輯符號。只有一類非邏輯符號,因此這裡的規則特別簡單。命題語言的解釋是賦值,即對句子字母的真值賦值。在謂詞邏輯中,我們將遇到除了賦值之外還包含其他元素的解釋。
- 將語義值賦予語言中較大的表示式的規則。對於命題邏輯,這些規則根據賦予較小公式的真值來賦予較大公式的真值。對於更復雜的語法(例如,用於謂詞邏輯),以更復雜的方式賦值。
一個擴充套件賦值根據賦值將真值賦予(或類似的命題語言)的分子公式。句子字母的賦值透過一組規則擴充套件以涵蓋所有公式。
我們可以給出一個(部分)賦值 作為
作為




(請記住,我們省略了上標來縮寫句子字母。)
通常,我們只對幾個句子字母的真值感興趣。賦予其他句子字母的真值可以是隨機的。
給定這個賦值,我們說
![{\displaystyle {\mathfrak {v}}[\mathrm {P_{0}} ]\ =\ {\mbox{True}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ebced4e093fec5549c19e71009bbfe61150bcb32)
![{\displaystyle {\mathfrak {v}}[\mathrm {P_{1}} ]\ =\ {\mbox{False}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a3abfe7bf710089ee4a80f78e285d70c5e2ac288)
![{\displaystyle {\mathfrak {v}}[\mathrm {P_{2}} ]\ =\ {\mbox{False}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/421c4ef2a1afc19e7f41c997a4c24a8d16ae5df1)
![{\displaystyle {\mathfrak {v}}[\mathrm {P_{3}} ]\ =\ {\mbox{False}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d825606df7242317bd0a3a3ded2cde67c2c0e41b)
實際上,我們可以將賦值定義為一個函式,其引數是句子字母,值是真值(因此稱為“真值”)。需要注意的是, 對於句子字母沒有固定的解釋或賦值。相反,我們為臨時使用指定解釋。
擴充套件解釋根據給定的解釋生成較長句子的真值。對於命題邏輯,解釋是賦值,因此擴充套件解釋是擴充套件賦值。我們定義賦值的擴充套件 如下。
如下。
對於所有句子字母
![{\displaystyle {\mbox{i.}}\quad {\overline {\mathfrak {v}}}[\varphi ]={\mathfrak {v}}[\varphi ].\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5501c945370a112d0e38c8d7c98fbd1957a0b2fd)
![{\displaystyle {\mbox{ii.}}\quad {\overline {\mathfrak {v}}}[\lnot \varphi ]\ =\ {\begin{cases}{\mbox{True}}&{\mbox{if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\mbox{False}};\\{\mbox{False}}&{\mbox{otherwise (i.e., if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\mbox{True).}}\end{cases}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d273839318730f629b864f7ee2b347b77a3d6d18)
![{\displaystyle {\mbox{iii.}}\quad {\overline {\mathfrak {v}}}[(\varphi \land \psi )]\ =\ {\begin{cases}{\mbox{True}}&{\mbox{if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\overline {\mathfrak {v}}}[\psi ]={\mbox{True}};\\{\mbox{False}}&{\mbox{otherwise}}.\end{cases}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/beee36cb5bd2db11eba8ff28102b09ab55455d54)
![{\displaystyle {\mbox{iv.}}\quad {\overline {\mathfrak {v}}}[(\varphi \lor \psi )]\ =\ {\begin{cases}{\mbox{True}}&{\mbox{if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\mbox{True}}\ {\mbox{or}}\ {\overline {\mathfrak {v}}}[\psi ]={\mbox{True}}\ {\mbox{(or both)}};\\{\mbox{False}}&{\mbox{otherwise}}.\end{cases}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f77ad1978590950a29bfe27fb9eb4961336aba1e)
![{\displaystyle {\mbox{v.}}\quad {\overline {\mathfrak {v}}}[(\varphi \rightarrow \psi )]\ =\ {\begin{cases}{\mbox{True}}&{\mbox{if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\mbox{False}}\ \ {\mbox{or}}\ \ {\overline {\mathfrak {v}}}[\psi ]={\mbox{True}}\ \ {\mbox{(or both)}};\\{\mbox{False}}&{\mbox{otherwise.}}\end{cases}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58609bb31fc2cf95154d2548c4186fc7b32222a83)
![{\displaystyle {\mbox{vi.}}\quad {\overline {\mathfrak {v}}}[(\varphi \leftrightarrow \psi )]\ =\ {\begin{cases}{\mbox{True}}&{\mbox{if}}\ {\overline {\mathfrak {v}}}[\varphi ]={\overline {\mathfrak {v}}}[\psi ];\\{\mbox{False}}&{\mbox{otherwise}}.\end{cases}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7c7992cb4fd370092b7de8c79b88af3968e0ec08)
我們將確定給定兩種賦值後此示例句子的真值。

首先,考慮以下賦值



(2) 根據條款 (i)
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {P} ]\ =\ {\mbox{True}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/78cdb69761b884faa72b30db3cff8fc4a327856f)
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {Q} ]\ =\ {\mbox{True}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d0efa7a915fac7ef962d0f2f6ccb28929c35307)
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {R} ]\ =\ {\mbox{False}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ec51568f30e8f378d378aff08b4e904288acc51c)
(3) 根據 (1) 和條款 (iii),
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {P} \land \mathrm {Q} ]\ =\ {\mbox{True}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/11cae0180cab0f6442791354b034e77a9fb6aebb)
(4) 根據 (1) 和條款 (iv),
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {Q} \lor \mathrm {R} ]\ =\ {\mbox{True}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a210367b901f58d46e5dc0bfa02614aed0e4a5cf)
(5) 根據 (4) 和條款 (v),
![{\displaystyle {\overline {\mathfrak {v}}}[\lnot (\mathrm {Q} \lor \mathrm {R} )]\ =\ {\mbox{False}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/16c3679ea35b0aaa6a8d6f46967b89f9d120ef0b)
(6) 根據 (3)、(5) 和條款 (v),
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {P} \land \mathrm {Q} \rightarrow \lnot (\mathrm {Q} \lor \mathrm {R} )]\ =\ {\mbox{False}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/254c7028855c2601b10b61357fa0c82fb832fae6)
因此,在我們的解釋中 (1) 是假的。
接下來,嘗試評估


(7) 根據條款 (i)
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {Q} ]\ =\ {\mbox{False}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fcb1a4a71fc929b4b5978178306540fac36eefe8)
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {R} ]\ =\ {\mbox{True}}\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1abbcf46ce1162c387f473031daa2f15c5f4be6)
(8) 根據 (7) 和條款 (iii),
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {P} \land \mathrm {Q} ]\ =\ {\mbox{False}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c7537741c53cf4db9db28ae3f3938c7dae033f2e)
(9) 根據 (7) 和條款 (iv),
(10) 根據 (9) 和條款 (v),
(11) 根據 (8)、(10) 和條款 (v),
![{\displaystyle {\overline {\mathfrak {v}}}[\mathrm {P} \land \mathrm {Q} \rightarrow \lnot (\mathrm {Q} \lor \mathrm {R} )]\ =\ {\mbox{True}}.\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eb0856841a0bf2fec31c009819a0109c99900644)
因此,(1) 在這種第二個解釋中是真的。請注意,我們這次做了一些比必要的工作更多。根據條款 (v),(8) 足以證明 (1) 的真值。
在形式語法中,我們之前給出了命題邏輯的形式語義。真值表是一種使用這種形式語法來計算給定解釋(對句子字母分配真值)的更大公式的真值的裝置。真值表也可以幫助澄清來自形式語法的材料。
我們從否定的真值表開始。它對應於我們對擴充套件評估的定義的條款 (ii)。
| |
|
|
|
| T |
F |
| F |
T |
|
T 和 F 分別代表真和假。每行代表一種解釋。第一列顯示解釋對句子字母 賦予的真值。在第一行,解釋對 賦予了真值。在第二行,解釋對 賦予了假值。
第二列顯示 在給定行解釋下的值。在第一行解釋下, 的值為假。在第二行解釋下, 的值為真。
我們可以更正式地說明。上面真值表的第一行表明,當 ![{\displaystyle {\mathfrak {v}}[\mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1f290d5e2a6545283f453fc40d450f3c912e081) = 真時,
= 真時,![{\displaystyle {\overline {\mathfrak {v}}}[\lnot \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b65176a279dec339d693de7e05a52411907cf87a) = 假。第二行表明,當 = 假時, = 真。我們也可以更簡單地說:否定句的真值與其被否定部分的真值相反。
= 假。第二行表明,當 = 假時, = 真。我們也可以更簡單地說:否定句的真值與其被否定部分的真值相反。
合取的真值表對應於我們對擴充套件賦值的定義中的第三條。
| |
|
|
|
|
| T |
T |
T |
| T |
F |
F |
| F |
T |
F |
| F |
F |
F |
|
這裡我們有兩個句子字母,因此有四種可能的解釋,每種解釋都用一行表示。前兩列顯示了四種解釋對 和 的賦值。第一行表示的解釋將兩個句子字母都賦值為真,依此類推。最後一列顯示了對 的賦值。你可以看到,當兩個合取式都為真時,合取式為真——否則合取式為假,即當至少有一個合取式為假時。
析取的真值表對應於我們對擴充套件賦值的定義中的第 (iv) 條。
| |
|
|
|
|
| T |
T |
T |
| T |
F |
T |
| F |
T |
T |
| F |
F |
F |
|
在這裡我們看到,當至少一個析取式為真時,析取式為真——否則析取式為假,即當兩個析取式都為假時。
條件句的真值表對應於我們對擴充套件賦值的定義中的第 (v) 條。
| |
|
|
|
|
| T |
T |
T |
| T |
F |
F |
| F |
T |
T |
| F |
F |
T |
|
當條件句的前件為假或後件為真(或兩者都為真)時,條件句為真。否則為假,即當條件句的前件為真而條件句的後件為假時。
雙條件句的真值表對應於我們對擴充套件賦值的定義中的第 (vi) 條。
| |
|
|
|
|
| T |
T |
T |
| T |
F |
F |
| F |
T |
F |
| F |
F |
T |
|
當雙條件句的兩部分具有相同的真值時,雙條件句為真。當雙條件句的兩部分具有相反的真值時,雙條件句為假。
我們將使用來自 形式語義 的相同示例句子。

我們按如下方式構建其真值表。
| |
|
|
|

|
|

|

|

|
| T |
T |
T |
T |
T |
F |
F |
| T |
T |
F |
T |
T |
F |
F |
| T |
F |
T |
F |
T |
F |
T |
| T |
F |
F |
F |
F |
T |
T |
| F |
T |
T |
F |
T |
F |
T |
| F |
T |
F |
F |
T |
F |
T |
| F |
F |
T |
F |
T |
F |
T |
| F |
F |
F |
F |
F |
T |
T |
|
當有三個命題字母時,我們需要八個賦值(以及真值表中的八行)來覆蓋所有情況。該表分部分構建示例語句。 列是基於 和 列構建的。  列是基於 和 列構建的。反過來,這也是其在下一列中否定之基礎。最後,最後一列是基於 和 列構建的。
列是基於 和 列構建的。反過來,這也是其在下一列中否定之基礎。最後,最後一列是基於 和 列構建的。
從該真值表中,我們看到當 和 都為真時,示例語句為假;其他情況下為真。
該表可以以更壓縮的格式編寫,如下所示。
| |
|
|
|
|
(1)
|
|
(4)
|
(3)
|

|
(2)
|

|
| T |
T |
T |
|
T |
|
F |
F |
|
T |
|
| T |
T |
F |
|
T |
|
F |
F |
|
T |
|
| T |
F |
T |
|
F |
|
T |
F |
|
T |
|
| T |
F |
F |
|
F |
|
T |
T |
|
F |
|
| F |
T |
T |
|
F |
|
T |
F |
|
T |
|
| F |
T |
F |
|
F |
|
T |
F |
|
T |
|
| F |
F |
T |
|
F |
|
T |
F |
|
T |
|
| F |
F |
F |
|
F |
|
T |
T |
|
F |
|
|
連線詞上方的數字不是真值表的一部分,而是顯示了列的填充順序。
在命題邏輯中,一個公式為真的解釋被稱為滿足該公式。在謂詞邏輯中,滿足的概念稍微複雜一些。一個公式是可滿足的 當且僅當它在至少一個解釋下為真(也就是說,當且僅當至少一個解釋滿足該公式)。真值表 的示例真值表顯示了以下語句是可滿足的。

為了更簡單的說明,公式 是可滿足的,因為它在任何將 賦值為 True 的解釋下都是真的。
我們用符號  來表示解釋 滿足 。如果
來表示解釋 滿足 。如果  不滿足
不滿足  則我們寫成
則我們寫成  。
。
滿足的概念也可以擴充套件到公式集。一個公式集是可滿足的,當且僅當存在一個解釋,使得該集中的每個公式在該解釋下都是真的(即,該解釋滿足該集中的每個公式)。
一個公式是 *不可滿足的*,當且僅當不存在一個解釋,使得該公式在該解釋下為真。一個簡單的例子是

你可以透過真值表輕鬆驗證,無論解釋對 賦值什麼真值,該公式都是假的。我們稱不可滿足的公式為 *邏輯假* 。可以認為命題邏輯中(但不包括謂詞邏輯)不可滿足的公式是 *重言式假* 。
一個公式是 *有效的*,當且僅當它在每個解釋下都為真。例如,

是有效的。你可以透過真值表輕鬆驗證,無論解釋對 賦值什麼,該公式都是真的。我們稱有效的句子為 *邏輯真* 。我們稱命題邏輯中(但不包括謂詞邏輯)有效的公式為 *重言式* 。
我們使用符號  來表示 是有效的,並且使用
來表示 是有效的,並且使用  表示 是無效的。
表示 是無效的。
當且僅當兩個公式在完全相同的解釋下為真時,它們才是等價的。您可以透過真值表輕鬆地確認任何滿足 的解釋也滿足  。此外,任何滿足 的解釋也滿足 。因此它們是等價的。
。此外,任何滿足 的解釋也滿足 。因此它們是等價的。
我們可以使用以下方便的符號來表示 和 是等價的。
-
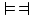
當且僅當以下成立時為真

一個論證是指一組被指定為前提的公式,以及被指定為結論的單個句子。直觀地說,我們希望這些前提共同構成相信結論的理由。就我們而言,一個論證是任何前提集加上任何結論。對於某些特別荒謬的論證來說,這可能有點人為,但論證的邏輯屬性並不取決於它是否荒謬,或者是否有人實際上確實或可能認為這些前提是相信結論的理由。我們認為論證好像有人確實或可能認為這些前提是結論的理由,而不管是否有人實際確實或可能這樣做。即使是空的前提集加上一個結論,也算是一個論證。
以下示例顯示了使用多種符號表示的相同論證。
- 符號 1
- 因此
- 符號 2
- ∴
- 符號 3

- 符號 4
 ∴
∴
一個論證是有效的當且僅當所有滿足所有前提的解釋也滿足結論。一個有效論證的結論是其前提的 *邏輯結果*。我們可以用  作為其前提集, 作為其結論來表達論證的有效性(或無效性),使用以下符號。
作為其前提集, 作為其結論來表達論證的有效性(或無效性),使用以下符號。
- (1)

- (2)

例如,我們有

論證的有效性,或邏輯結果,是我們構建邏輯直覺的中心概念。我們想知道我們的論證是否是有力的論證,也就是說,它們是否代表了良好的推理。我們想知道一個論證的前提是否構成了相信結論的充分理由。有效性是良好論證的一個重要特徵。它不是唯一的必要特徵。至少有一個錯誤前提的有效論證是無用的。有效性是真值保持特徵。它不告訴我們結論是正確的,只告訴我們論證的邏輯特徵是,如果前提是正確的,那麼結論就是正確的。具有正確前提的有效論證是 *健全的*。
一個好的論證還需要一些不太正式的特徵。僅僅因為前提是正確的,並不意味著它們是可信的,我們有理由相信它們,或者我們可以收集證據來支援它們。還應該注意的是,有效性只適用於某些型別的論證,特別是 *演繹* 論證。演繹論證旨在有效。演繹論證的典型例子是數學證明。歸納論證,以科學論證為典型例子,並不旨在有效。前提的真實性並不旨在保證結論的真實性。相反,前提的真實性旨在使結論的真實性高度可能或有可能。在科學中,我們並不打算提供數學證明。相反,我們收集證據。
對於每個有效的公式,都存在一個相應的有效論證,其結論是有效的公式,前提集為空集。因此

當且僅當

對於每個具有有限多個前提的有效論證,都存在一個相應的有效公式。考慮一個具有 作為結論,其前提為  的有效論證。然後
的有效論證。然後

那麼,就有對應的有效公式

對於有效的論證
- ∴
有以下有效的公式

您可能會看到一些文字將我們的箭頭 理解為 “蘊涵”,並使用 “蘊涵” 作為 “條件句” 的替代詞。這通常被視為用詞不當。在日常英語中,以下句子被認為是語法正確的
- (3) '有煙就意味著有火'。
- (4) '有煙' 蘊涵 '有火'。
在 (3) 中,我們有一個事實或命題或其他東西(哲學家們現在似乎最喜歡的是命題),它蘊涵了同類的另一個事實或命題。在 (4) 中,我們有一個句子蘊涵了另一個句子。
但是以下句子被認為是不正確的
- 有煙蘊涵有火。
這裡,與 (3) 相比,沒有引號。沒有主體在進行蘊涵,也沒有客體被蘊涵。相反,我們正在用較小的句子構成一個更大的句子,就像 “蘊涵” 是一個語法連詞,例如 “當且僅當”。
因此,邏輯學家傾向於避免使用 “蘊涵” 來表示 條件句。相反,他們使用 “蘊涵” 來表示 具有邏輯結果,並使用 “蘊涵” 來表示 有效的論證。這樣做時,他們遵循的是 (4) 的模型,而不是 (3) 的模型。特別是,他們將 (1) 和 (2) 理解為 ' 蘊涵(或不蘊涵) 。
一個包含 n 個句子字母的公式,其 真值表 中需要  行。對於一個包含 m 行的真值表,有
行。對於一個包含 m 行的真值表,有  種可能的公式。因此,對於一個包含 n 個字母的句子,
種可能的公式。因此,對於一個包含 n 個字母的句子, ,可能的公式數量為
,可能的公式數量為  。
。
例如,一個句子字母有四種可能的公式(需要一個兩行真值表),而兩個句子字母有 16 種可能的公式(需要一個四行真值表)。我們用以下表格來說明這一點。編號列代表主連線符列的不同可能性。
| |
|
|
(i) |
(ii) |
(iii) |
(iv) |
| T |
T |
T |
F |
F |
| F |
T |
F |
T |
F |
|
列 (iii) 是之前介紹的否定公式 earlier。
| |
|
|
|
(i) |
(ii) |
(iii) |
(iv) |
(v) |
(vi) |
(vii) |
(viii) |
(ix) |
(x) |
(xi) |
(xii) |
(xiii) |
(xiv) |
(xv) |
(xvi) |
| T |
T |
T |
T |
T |
T |
T |
T |
T |
T |
F |
F |
F |
F |
F |
F |
F |
F |
| T |
F |
T |
T |
T |
T |
F |
F |
F |
F |
T |
T |
T |
T |
F |
F |
F |
F |
| F |
T |
T |
T |
F |
F |
T |
T |
F |
F |
T |
T |
F |
F |
T |
T |
F |
F |
| F |
F |
T |
F |
T |
F |
T |
F |
T |
F |
T |
F |
T |
F |
T |
F |
T |
F |
|
列 (ii) 代表析取公式,列 (v) 代表條件句,列 (vii) 代表雙條件句,列 (viii) 代表合取。
我們現在開始討論一個問題:是否擁有足夠的連線詞來表達任意數量的句子字母的所有公式。請記住,每一行代表一個賦值。我們可以透過將賦值為真值的那個句子字母進行合取,並將賦值為假值的句子字母進行否定,然後將這些結果進行合取來表達這個賦值。上面第二個表格中的四個賦值可以表達為:



現在,我們可以透過對公式值為真的賦值進行析取來表達任意公式。例如,我們可以用以下公式來表達第 (x) 列:
- (1)

你可以透過完成真值表來確認這個公式是否產生了預期的結果。當 (a) 為真且 為假,或 (b) 為假且 為真時,這個公式為真。有一個更簡單的表達方法: 。想出一個簡單的表達任意公式的方法可能需要一些洞察力,但至少我們有一種自動機制可以找到某種方法來表達它。
。想出一個簡單的表達任意公式的方法可能需要一些洞察力,但至少我們有一種自動機制可以找到某種方法來表達它。
現在讓我們考慮第二個例子。我們想表達一個由 , 和 組成的公式,並且我們希望這個公式只在以下三個賦值下為真值。
|
|
|
|
(i) |
|
(ii) |
|
(iii) |
| |
|
|
真 |
|
假 |
|
假 |
| |
|
|
真 |
|
真 |
|
假 |
| |
|
|
假 |
|
假 |
|
真 |
我們可以將產生真值的三個條件表達為



現在我們需要說第一個條件成立,或者第二個條件成立,或者第三個條件成立。
- (2)

你可以透過真值表驗證它是否產生了想要的結果,即該公式僅在上文的解釋中為真。
這種表達任意公式的技術不適用於在所有解釋中都為假的公式。我們至少需要一個解釋結果為真,才能開始這個公式。然而,我們可以使用任何永假的公式來表達這些公式。 就足夠了。
正規化提供了一個標準化的表達規則,任何公式都等效於符合該規則的公式。在下文中,將定義文字為句子字母或其否定(例如  和
和  以及
以及  和
和  )。
)。
我們說一個公式處於析取正規化,如果它是一個文字的合取的析取。例如  。為了這個定義的目的,我們允許所謂的退化的析取和合取,它們只包含一個析取項或合取項。因此,我們將 視為處於析取正規化,因為它是一個退化的(單值)析取,它包含一個退化的(單值)合取。可以透過將其轉換為等效公式
。為了這個定義的目的,我們允許所謂的退化的析取和合取,它們只包含一個析取項或合取項。因此,我們將 視為處於析取正規化,因為它是一個退化的(單值)析取,它包含一個退化的(單值)合取。可以透過將其轉換為等效公式  來消除退化。為了這個定義的目的,我們還允許多值的析取和合取,例如
來消除退化。為了這個定義的目的,我們還允許多值的析取和合取,例如  。上面顯示了一種找到任意公式的析取正規化的方法。
。上面顯示了一種找到任意公式的析取正規化的方法。
在命題邏輯中,另一種常見的正規化是合取正規化。如果一個公式是文字的析取的合取,那麼它就處於合取正規化。例如  。同樣地,我們可以用合取正規化表達任意公式。首先,取公式求值為 False 的那些賦值。對於每個這樣的賦值,形成一個析取,這個析取包含賦值為 False 的句子字母以及賦值為 True 的句子字母的否定。對於賦值
。同樣地,我們可以用合取正規化表達任意公式。首先,取公式求值為 False 的那些賦值。對於每個這樣的賦值,形成一個析取,這個析取包含賦值為 False 的句子字母以及賦值為 True 的句子字母的否定。對於賦值
- : False
- : True
- : False
我們形成析取

任意公式的合取正規化表示式是所有與公式求值為 False 的解釋相匹配的這些析取的合取。上面 (1) 的合取正規化等價形式是

上面 (2) 的合取正規化等價形式是

否定和合取足以表達其他三個連線詞,以及任何任意公式。
-

-

-

否定和析取足以表達其他三個連線詞,實際上可以表達任何任意公式。
-

-

-


否定和條件足以表達其他三個連線詞,實際上可以表達任何任意的公式。
-
-

-

否定和雙條件不足以表達其他三個連線詞。
我們已經看到,三對連線詞中的每一對都可以共同表達任意公式。由此引出一個問題:是否可以用一個連線詞來表達任意公式?答案是肯定的,但不能用我們現有的任何連線詞。如果在 中新增以下兩個二元連線詞中的任何一個,那麼它將足以表達任意公式。
選擇否定,有時被稱為NAND。這個連線詞通常用謝弗豎線符號表示,寫成  (一些作者使用 ↑)。在 中臨時新增符號
(一些作者使用 ↑)。在 中臨時新增符號  ,並令
,並令 ![{\displaystyle {\mathfrak {v}}[(\varphi \mid \psi )]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c2373a724763dbb02fd1322fd9d7a2f14a1633b9) 在 或 中至少有一個為假時為真。它的真值表如下:
在 或 中至少有一個為假時為真。它的真值表如下:
| |
|
|
|

|
| T |
T |
F |
| T |
F |
T |
| F |
T |
T |
| F |
F |
T |
|
現在我們有以下等價關係。
-

-

-

-

-

聯合否定,有時稱為NOR。暫時將符號  新增到 中,並令
新增到 中,並令 ![{\displaystyle {\mathfrak {v}}[(\varphi \downarrow \psi )]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/832d14657b0129129e58f18ae7512a641f7debf8) 在 和 都為假時為真。它的真值表如下
在 和 都為假時為真。它的真值表如下
| |
|
|
|

|
| T |
T |
F |
| T |
F |
F |
| F |
T |
F |
| F |
F |
T |
|
現在我們有以下等價關係。
-

-

-

-

-

這裡列出了一些比較有名的、歷史重要的或有用的等價和同義反覆。這些等價和同義反覆可以新增到連線詞的相互定義中列出的等價和同義反覆。我們可以在這裡繼續列出很多,但會盡量使列表保持簡潔。請記住,對於 和 的每個等價,都存在一個相關的同義反復  .
.
每個公式只有一個真值。
 排中律
排中律 矛盾律
矛盾律
算術中的一些熟悉定律在命題邏輯中也有類似的定律。
條件和雙條件(但不是合取和析取)是自反的。


合取、析取和雙條件(但不是條件)是可交換的。
-
-

-

合取、析取和雙條件式(但非條件式)都是結合的。






我們列出了十條分配律。其中,最重要的可能是合取和析取互相分配,以及條件式自身分配。
-





-













合取、條件和雙條件(但不包括析取)是傳遞的。



這些重言式和等價式主要與條件句相關。



 條件加法
條件加法 條件加法
條件加法-
 逆否命題
逆否命題
 匯出規則
匯出規則
這些重言式和等價關係大多與雙條件語句有關。
 雙條件加法
雙條件加法 雙條件加法
雙條件加法


我們重複可表達性部分的可表達性中的德摩根定律,並新增兩種附加形式。我們還列出了一些額外的重言式和等價式。
 冪等對於合取
冪等對於合取 冪等對於析取
冪等對於析取 析取加法
析取加法 析取加法
析取加法
- 德摩根定律
- 德摩根定律

 德摩根定律
德摩根定律 德摩根定律
德摩根定律-
 雙重否定律
雙重否定律
以下兩個原則將在後面的頁面中用於構建我們的推導系統。它們很容易被證明,但由於它們既不是重言式也不是等價式,所以僅僅用真值表不足以做到這一點。我們在這裡不會嘗試證明。
令 和 都是公式,令 是一組公式。

令 和 都是公式,令 是一組公式。


本頁將使用在 Formal Logic/Sentential Logic/Formal Syntax 的“Additional terminology” 部分介紹的 occurrence 和 subformula 概念。這些概念自那時起很少使用,因此您可能需要回顧一下。
我們已經介紹了一些重言式,例如
- (1)

使用元變數  和 替換 (1) 中的 和
和 替換 (1) 中的 和  。這產生了形式
。這產生了形式
- (2)

事實證明,任何匹配此形式的公式都是重言式。因此,例如,令  和
和  。那麼,
。那麼,
- (3)

是一個重言式。此過程可以推廣到所有重言式:對於任何重言式,透過用不同的元變數(如(2)中所示,用希臘字母表示)替換每個句子字母來找到其顯式形式。我們可以將其稱為 *重言式形式*,它是元邏輯表示式而不是公式。此重言式形式的任何例項都是重言式。
前面說明了如何透過重言式形式從舊重言式生成新重言式。在這裡,我們將展示如何不借助重言式形式來生成重言式。為此,我們定義了公式的替換例項。任何重言式的替換例項也是重言式。
首先,我們定義了公式對句子字母的簡單替換例項。令 和 是公式,而  是句子字母。*簡單替換例項*
是句子字母。*簡單替換例項* ![{\displaystyle \varphi [\pi /\psi ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d2eebfcef8dc9c38d2c05d12e2f5f0a0e35616de) 是將 中 *所有* 出現的 替換為 所得到的結果。*公式對句子字母的替換例項* 是簡單替換例項鏈的結果。特別是,從 開始的零個簡單替換例項鏈是替換例項,實際上就是 本身。因此,任何公式都是其自身的替換例項。
是將 中 *所有* 出現的 替換為 所得到的結果。*公式對句子字母的替換例項* 是簡單替換例項鏈的結果。特別是,從 開始的零個簡單替換例項鏈是替換例項,實際上就是 本身。因此,任何公式都是其自身的替換例項。
事實證明,如果 是重言式,則任何簡單替換例項 也是重言式。如果我們從重言式開始並生成簡單替換例項鏈,那麼鏈中的每個公式也是重言式。因此,重言式的任何(不一定是簡單的)替換例項也是重言式。
再次考慮 (1)。我們將  替換為 (1) 中所有出現的 。這給了我們 (1) 的以下簡單替換例項
替換為 (1) 中所有出現的 。這給了我們 (1) 的以下簡單替換例項
- (4)

在這裡,我們將 代替 。這樣我們就得到了 (3) 作為 (4) 的一個簡單的替換例項。由於 (3) 是兩個簡單替換例項鏈的結果,因此它是 (1) 的一個 (非簡單) 替換例項。由於 (1) 是一個重言式,所以 (3) 也是一個重言式。我們可以將替換連結串列示為
![{\displaystyle \mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )[\mathrm {Q} /\mathrm {R} \land \mathrm {S} ][\mathrm {P} /\mathrm {P} \lor \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81271051059723595e8d452d27da89f1af994693)
再舉一個例子,同樣從 (1) 開始。我們想要得到
- (5)

我們的第一次嘗試可能是用 代替 ,
- (6)

這確實是一個重言式,但它不是我們想要的那個。相反,我們在 (1) 中用 代替 ,得到

現在用 代替 ,得到

最後,將 代入 得到我們想要的結果,即 (5)。由於 (1) 是重言式,所以 (5) 也是重言式。我們可以將替換連結串列示為
![{\displaystyle \mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )[\mathrm {P} /\mathrm {R} ][\mathrm {Q} /\mathrm {P} ][\mathrm {R} /\mathrm {Q} ]\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3a6dac03fc4768317ce9e57ee664b4a38cd4dfcf)
我們可以將一系列簡單替換壓縮成單個複雜替換。設 、 、
、 、... 為公式;設
、... 為公式;設  、
、 、... 為句子字母。我們定義一個*公式對句子字母的同步替換例項*
、... 為句子字母。我們定義一個*公式對句子字母的同步替換例項* ![{\displaystyle \varphi [\pi _{1}/\psi _{1},\ \pi _{2}/\psi _{2},\ ...]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/97abe1a722c3e0bec01154fbe24631634c4e7ecf) 為從 開始,同時將 替換為 、 替換為 、.... 我們可以重新生成我們的示例。
為從 開始,同時將 替換為 、 替換為 、.... 我們可以重新生成我們的示例。
之前生成的公式 (3) 是
![{\displaystyle \mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )[\mathrm {P} /\mathrm {P} \lor \mathrm {Q} ,\mathrm {Q} /\mathrm {R} \land \mathrm {S} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/86e6d375945f1499a1f619e0362ac3cb4bec2b09)
類似地,(5) 是
![{\displaystyle \mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )[\mathrm {P} /\mathrm {Q} ,\ \mathrm {Q} /\mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e422947c6c27eebd07aa0cf66ed74321e18f1561)
最後 (6) 是
![{\displaystyle \mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )[\mathrm {Q} /\mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dfca8b9e7c07ffb3fd96e9180eda01663234be6f)
當我們進入謂詞邏輯時,不會有同時替換例項可用。這就是我們透過引用一系列簡單替換例項而不是同時替換例項來定義 *替換例項* 的原因。
我們之前在 命題連線詞的性質 中看到了以下等價關係
- (7)
然後您可能會期望以下等價關係


這個預期是正確的;這兩個公式是等價的。令 和 為等價公式。令  為一個公式,其中 作為子公式出現。最後,令
為一個公式,其中 作為子公式出現。最後,令  為在
為在  中至少替換一個(不一定是全部) 為 所得的結果。那麼 和 是等價的。這種替換被稱為交換。
中至少替換一個(不一定是全部) 為 所得的結果。那麼 和 是等價的。這種替換被稱為交換。
另一個例子,假設我們想要生成等價關係
- (8)

我們注意到以下等價關係
- (9)


這兩個公式可以透過真值表來驗證,或者更簡單地,將 (7) 中的兩個公式中的 替換為 來確認。
這種替換確實將 (9) 確立為一個等價關係。我們已經注意到, 和 等價當且僅當 是一個重言式。根據 (7),我們得到重言式

然後我們的替換得到

這也是一個重言式。那麼相應的等價關係就是 (9)。
根據 (9),我們現在可以將 的後件替換為其等價關係。這將產生我們想要的等價關係,即 (8)。
每個與重言式等價的公式也是重言式。因此,在重言式中交換等價的子公式將得到一個重言式。例如,我們可以使用 (7) 的替換例項
-

以及我們之前在 命題聯結詞性質 中看到的重言式

得到

作為一個新的重言式。
作為示例,我們將使用 聯結詞的可互定義性 來用條件語句和否定來表達
- (10)

。
基於
-
我們得到了替換例項
-

這反過來又允許我們替換 (10) 中的相應子公式,得到
- (11)

等價關係
-
以及適當的替換,給了我們
- (12)

與 (11) 等價。
最後,應用
-
以及適當的替換,得到我們的最終結果

本頁提出了兩個論點。
- 給定一個公式,將子公式替換為等價公式的結果是與給定公式等價的公式。
這些斷言並非微不足道的觀察或簡單的真值表的結論。它們是需要證明的實質性斷言。證明可以在許多標準的元邏輯教科書中找到,但此處不予展示。
頁面 命題語言 簡要介紹了英語和 之間的翻譯。我們將在本文中更詳細地探討這一問題。
在下文中,我們假設將以下英語句子分配給 的命題字母
 2 是一個質數。
2 是一個質數。 2 是一個偶數。
2 是一個偶數。 3 是一個偶數。
3 是一個偶數。
將 翻譯成英語的規範方法是“並非”。根據上述分配,
- (1)
翻譯成
- 並非 2 是一個質數。
但我們通常用“不是”或在詞尾加“不”來表示英語中的否定。因此,(1) 也可以翻譯成以下兩種方式:
- 2 不是一個質數。
- 2 不是一個質數。
將 翻譯成英語的規範方法是“如果……那麼……”。因此
- (2)
翻譯成英語為
- (3) 如果 2 是一個質數,那麼 2 是一個偶數。
人們對規範翻譯提出了一些異議,我們的例子可能說明了這個問題。將 (3) 視為真似乎很奇怪;然而,我們的語義規則確實將 (2) 視為真(因為 和 都是真的)。我們可能希望,如果一個條件語句及其前件為真,那麼後件也是真的,因為前件為真。也許我們希望有一個通用的規則
- (4) 如果 x 是一個質數,那麼 x 是一個偶數
為真——但這條規則顯然是假的。無論如何,我們通常希望前件的真值(如果它確實是真)與結論的真值(如果它確實是真)在某種程度上是相關的。(2) 是一個例外,因為一個數字是質數與這個數字是偶數之間通常不存在相關性。
的條件式 被稱為實質條件,以區別於嚴格條件或反事實條件。 關聯邏輯試圖定義一個符合這些反對意見的條件式。 另請參閱斯坦福哲學百科全書關於關聯邏輯的條目。
如今人們普遍認為,並非表達的語言使用的所有方面都屬於其語言意義的一部分。 有人認為,將“if”解讀為實質條件式的反對意見是基於會話含義,而不是基於“if”的意義。 有關更多資訊,請參閱斯坦福哲學百科全書關於會話含義的條目。 儘管這更像是一個簡化假設,但我們將採用這種觀點。 我們也可以在我們的辯護中指出,翻譯不需要完全準確才能有用。 即使我們的簡化假設是錯誤的, 仍然是 中最接近“if”的表達方式。 還應該注意的是,在數學陳述和證明中,數學家始終將“if”用作實質條件式。 他們接受 (2) 和 (3) 作為彼此的翻譯,並且不覺得將 (3) 視為真有什麼奇怪。
“If”可以出現在條件式的開頭或中間。 “Then”可以省略。 因此,以下兩者(以及 (3))都翻譯成 (2)。
- 如果 2 是一個素數,那麼 2 是一個偶數。
- 2 是一個偶數,如果 2 是一個素數。
我們不將“implies”翻譯成。 特別地,我們拒絕
- 2 是一個素數,蘊含 2 是一個偶數。
因為它是語法上不正確的,因此不能翻譯成 (2)。 有關更多詳細資訊,請參閱蘊含部分的有效性。
英文
- (5) 2 是一個素數,當且僅當 2 是一個偶數
等同於英文
- 如果 2 不是一個偶數,那麼 2 不是一個素數。
這反過來翻譯成 為
- (6)
我們在條件式部分的命題連線詞的性質中看到,(6) 等同於
- (7)
許多邏輯書籍將此作為 (5) 翻譯成 的首選翻譯。 這允許使用方便的規則“if”始終引入一個前件,而“only if”始終引入一個後件。
與“if”一樣,“only if”也可以出現在條件式的第一個位置或中間位置。 (5) 等同於
- 當且僅當 2 是一個偶數,2 才是一個素數。
“如果”——以及類似的表達,例如“假設”和“如果”——可以與“if”等效地使用。 因此,以下每個都翻譯成 為 (2)。
- 2 是一個偶數,如果 2 是一個素數。
- 2 是一個偶數,假設 2 是一個素數。
- 如果 2 是素數,那麼 2 是偶數。
在 "provided that" 前面加上 "only" 與在 "if" 前面加上 "only" 意義相同。因此以下每個句子都可翻譯為 ,如 (6) 或 (7)。
- 只有當 2 是偶數時,2 才是素數。
- 只有假設 2 是偶數時,2 才是素數。
- 只有當 2 是偶數時,2 才是素數。
將 翻譯成英文是 "[either] ... or ..."(其中 "either" 可選)。因此
- (8)
翻譯成英語為
- (9) 2 是素數或 2 是偶數
或者
- 2 是素數或 2 是偶數。
我們在 可表達性的連線詞互定 部分看到 (8) 等價於
正如將 "if" 理解為 會引發爭議,將 "or" 理解為 也存在類似的爭議。我們將再次做出簡化的假設,忽略這些爭議。
英文中的 "or" 既有包含性也有——有點爭議——排他性用法。當至少有一個析取式為真時,包含性或 為真;當恰好有一個析取式為真時,排他性或 為真。 運算子與包含性用法相匹配。包含性用法在否定中尤為明顯。如果布什總統承諾不入侵伊朗或朝鮮,即使是最優秀的共和黨說客也不會聲稱他可以透過入侵兩國來履行諾言。對 (9) 的排他性解讀翻譯成 如下所示:

或者更簡單地(不太直觀)為
在英文中,可以使用 "or" 進行縮略。因此,(8) 翻譯為
- 2 是素數或偶數。
同樣地,
翻譯為
- 2 或 3 是偶數。
"Unless" 與 "if not" 含義相同。因此
- (10)

翻譯為
- (11) 2 是素數,除非 2 是偶數。
以及
- (12) 除非 2 是偶數,否則 2 是素數。
我們在連線詞的可互定義性部分的表達能力中看到 (10) 等價於 (8)。許多邏輯書籍將 (8) 作為 (11) 或 (12) 翻譯成 的首選翻譯。
在聯合否定部分的表達能力中,我們暫時將 新增到 作為聯合否定的連線詞。如果我們仍然可以使用該連線詞,我們可以翻譯
- 2 不是素數,也不是偶數。
為
- .
然而,由於 實際上並不在 的詞彙表中,我們需要進行改寫。以下任一方法都可行
- (13) .
- (14)
 .
.
與“或”一樣,也適用於相同的望遠鏡。
- 2 既不是素數,也不是偶數。
翻譯成 為 (13) 或 (14)。同樣地,
- 2 和 3 都不為偶數。
翻譯為以下任一:
- .
 .
.
將 翻譯成英文的典型形式是“‘[both] … and …’” (其中“both” 可選)。因此
- (15)
翻譯成英語為
- 2 是素數,並且 2 是偶數。
或者
- 2 是素數,並且 2 是偶數。
我們將“and” 翻譯成 的做法並不特別有爭議。但是,“and” 有時用於表達時間順序。以下兩個句子
- 她結婚了,然後懷孕了。
- 她懷孕了,然後結婚了。
通常聽起來有很大不同。
“And” 與“or” 一樣,具有相同的望遠鏡效果。
- 2 既是素數,又是偶數。
翻譯成 ,如 (15)
- 2 和 3 都是偶數。
翻譯成
- .
到英文的標準翻譯是 "... if and only if ...". 因此
- (16)
翻譯成英語為
- 2 是一個質數當且僅當 2 是一個偶數。
英文句子
- (17) 2 是一個質數當且僅當 2 是一個偶數
是
- 2 是一個質數如果 2 是一個偶數,並且 2 是一個質數只有當 2 是一個偶數
的簡化形式,翻譯成

或更簡潔地表示為等效公式
- (18) .
我們在 連線詞的可互定義性 部分看到了, (18) 等價於 (16)。關於 'if' 的物質解釋和非物質解釋的問題也適用於 'if and only if'。
數學家和有時其他人使用 'iff' 作為 'if and only if' 的簡寫形式。所以
- 2 是一個質數當且僅當 2 是一個偶數
是 (17) 的簡寫形式,並翻譯成 (16)。
在 有效性 中,我們引入了公式和論證的有效性概念。在命題邏輯中,有效的公式是重言式。到目前為止,我們可以透過以下方式顯示公式 是有效的(重言式)。
- 為 製作真值表。
- 獲得 作為已知有效的公式的替換例項。
- 透過將等價交換應用於已知有效的公式來獲得 。
然而,這些方法在謂詞邏輯中失效,因為謂詞沒有真值表。如果沒有替代方法,我們就無法使用第二種和第三種方法,因為它們依賴於知道其他公式的有效性。顯示公式有效的另一種方法——不使用真值表——是使用推導。本頁和後面的頁面介紹了這種技術。注意,聲稱推導顯示論證有效假設了一個健全的推導系統,參見下面的健全性。
推導是一系列編號的行,每行包含一個帶有註釋的公式。註釋提供了將該行新增到推導中的理由。推導是數學證明的高度形式化的模擬——或者可能是模型。
典型的推導系統將允許以下型別的行
- 一行可以是公理。推導系統可以指定一組公式作為公理。這些公理被接受為任何推導的真值。對於命題邏輯,公理集是所有重言式的固定子集。
- 一行可以是假設。推導可以包含幾種型別的假設。以下內容涵蓋了標準情況。
- 前提。在試圖證明論證的有效性時,可以假設該論證的前提。
- 用於子推導的臨時假設。這種假設旨在僅在推導的一部分中生效,並且必須在推導被認為完成之前被解除(變為無效)。子推導將在後面的頁面中介紹。
- 一行可以是將推理規則應用於先前行的結果。推理是先前行的語法轉換,用於生成新行。推理必須遵循推導系統定義的固定模式之一。這些模式是系統的推理規則。其思想是,任何符合推理規則的推理都應該是有效的論證。
我們在形式語義學中注意到,像 這樣的形式語言可以通過幾種替代甚至相互競爭的語義規則集來解釋。對於給定的語法語義對,也可以定義多個推導系統。包含形式語法、形式語義和推導系統的三元組是一個邏輯系統。
這樣的形式語言可以通過幾種替代甚至相互競爭的語義規則集來解釋。對於給定的語法語義對,也可以定義多個推導系統。包含形式語法、形式語義和推導系統的三元組是一個邏輯系統。
推導旨在證明論證的有效性。零前提論證的推導旨在證明其結論是有效的公式——在命題邏輯中,這意味著證明它是重言式。對於給定的邏輯系統,如果推導系統實現了這些目標,則稱該推導系統為健全。也就是說,一個推導系統是健全(具有健全性屬性)的,如果其推導系統中可推導的每個公式(和論證)都是有效的(給定語法和語義)。
推導系統另一個理想的特性是完備性。對於給定的邏輯系統,如果其推導系統可以推匯出所有有效的公式,則稱該推導系統為完備。但是,對於某些邏輯,不存在任何推導系統是或可以是完備的。
健全性和完備性是重要的結果。它們的證明在此不予給出,但可以在許多標準的元邏輯教科書中找到。
 符號有時被稱為轉置符號,特別是語義轉置符號。我們之前介紹了該符號的以下三種用法。
符號有時被稱為轉置符號,特別是語義轉置符號。我們之前介紹了該符號的以下三種用法。
|
|
(1)
|
|

|
|
滿足 . |
|
|
(2)
|
|

|
|
是有效的。 |
|
|
(3)
|
|

|
|
蘊含(作為邏輯結果) . |
其中 是一個賦值,而  是一組前提,如有效性中所介紹的。
是一組前提,如有效性中所介紹的。
推導有語義轉置符號的對應物,即語法轉置符號。上面的專案 (1) 沒有語法對應物。但是,上面的 (2) 和 (3) 有以下對應物。
|
|
(4)
|
|

|
|
是可證的。 |
|
|
(5)
|
|

|
|
證明(具有推導結果). |
專案(4)的情況當且僅當存在 從無前提的正確推導。同樣地,(5)的情況當且僅當存在 的正確推導,它將 的成員作為前提。
上面(4)和(5)的否定是
|
|
(6)
|
|

|
|
|
(7)
|
|

|
現在我們可以定義健全性和完備性如下


推理規則將以以下示例的格式顯示。
- 條件消去 (CE)

這個推理規則的名稱是“條件消去”,縮寫為“CE”。如果在線上方的公式形式作為推導中的活動行出現,則可以應用此規則。這些稱為此推理的前件行。應用此規則將新增一個具有線上下方的形式的公式。這稱為此推理的後件行。新推導的行文字的註釋是前件行的行號和縮寫“CE”。
注意。您可能會看到前提行和結論行來代替前件行和後件行。您也可能會看到其他術語,因為大多數教科書在這裡避免給出任何特殊的術語。
每個命題連線詞將有兩個推理規則,分別對應以下型別。
- 一個引入規則。給定連線詞的引入規則允許我們推匯出一個以給定連線詞作為主連線詞的公式。
- 一個消去規則。給定連線詞的消去規則允許我們使用已經出現在推導中的公式,該公式以給定連線詞作為主連線詞。
三個規則(否定引入、否定消去和條件引入)將推遲到下一頁。這些是所謂的放電規則,將在我們討論子推導時解釋。
三個規則(合取消去、析取引入和雙條件消去)將分別有兩個形式。我們任意地將這兩種模式視為同一規則的形式,而不是獨立的規則。
本頁上推理的有效性可以透過真值表來證明。
否定引入 (NI)
- 推遲到下一頁。
否定消去 (NE)
- 推遲到下一頁。
合取引入 (KI)

合取引入傳統上被稱為並置或合取。
合取消去,形式一 (KE)

合取消去,形式二 (KE)
合取消去傳統上被稱為簡化。
析取引入,形式一 (DI)

析取引入,形式二 (DI)
析取引入傳統上被稱為加法。
析取消去 (DE)



析取消去傳統上被稱為案例分離。
條件句引入 (CI)
- 推遲到下一頁。
條件消去 (CE)
條件句消去傳統上被稱為拉丁語名稱肯定前件或不太常使用地被稱為肯定前件。
雙條件句引入 (BI)

雙條件句消去,形式一 (BE)
雙條件句消去,形式二 (BE)

推理規則很容易應用。從以下兩行
- (1)

以及
- (2)
我們可以使用條件消去來新增
- (3)

到推導中。
註釋將是 (1) 和 (2) 的行號以及條件消去的縮寫,即“1, 2, CE”。前件行的順序並不重要;無論 (1) 出現於 (2) 之前還是之後,該推理都是允許的。
必須記住,推理規則是嚴格的句法規則。語義上明顯的變體是不允許的。例如,不允許從 (1) 和
- (4)
推匯出 (3)。然而,你可以透過首先推匯出
- (5)
以及
- (6)
使用合取消去 (KE) 從 (1) 和 (4) 中得到 (3)。然後,你可以透過合取引入 (KI) 推匯出 (2),最後像以前一樣透過條件消去 (CE) 從 (1) 和 (2) 中推匯出 (3)。一些推導系統有一個規則,通常稱為重言式蘊涵,允許你推匯出先前行中的任何重言式結論。然而,這應該被視為一種(誠然有用)的縮寫。在後面的頁面中,我們將實現這種縮寫的限制版本。
通常情況下,透過使用消去規則來分解前提、其他假設(將在後面的頁面中介紹)——然後繼續分解結果,這樣做是很有用的。假設這就是為什麼我們對 (1) 和 (2) 應用 CE,那麼推匯出
- (7)

以及
- (8)

透過對 (3) 應用雙條件消去 (BE)。為了進一步分解它,你可能嘗試推匯出  或
或  ,這樣你就可以對 (7) 或 (8) 應用 CE。
,這樣你就可以對 (7) 或 (8) 應用 CE。
如果你知道你想要推導哪一行,你可以透過使用引入規則來構建它。這是從 (5) 和 (6) 中推匯出 (2) 的策略。
我們的推導包含兩種型別的元素。
- 行號。這允許在後面引用該行。
- 公式。推導的目的是推匯出公式,這是在該行推匯出的公式。
- 註釋。它指定了將公式輸入推導中的理由。
- 行號和公式之間的垂直線。這些用於設定我們將在下一模組中介紹的子推導。
- 將前提和臨時假設與其他行隔開的水平線。當我們進入謂詞邏輯時,使用前提和臨時假設會有限制。以一種易於識別的格式設定它們有助於遵守這些限制。
我們通常非正式地談論公式,就好像它是整行一樣,但該行還包括行號和註釋。
前提的標註是“前提”。 我們要求推導中使用到的所有前提都出現在第一行。 不允許任何非前提行出現在前提之前。 理論上,一個論證可以有無窮多個前提。 但是,推導只有有限多行,所以推導中只能使用有限多個前提。 我們不要求所有前提都出現在其他行之前。 對於有無窮多個前提的論證來說,這是不可能的。 但我們確實要求推導中出現的所有前提都出現在任何其他行之前。
要求推導中使用到的前提出現在其第一行,比絕對必要的要求更嚴格。 然而,當我們進入謂詞邏輯時,某些限制將變得必要,這使得這個要求至少是一個有用的約定。
我們在上一模組中介紹了除兩條推理規則之外的所有推理規則,並在下一模組中介紹另外兩條推理規則。
這個推導系統沒有任何公理。
我們將為以下論證構造一個推導
 ∴
∴
首先,我們將前提輸入到推導中
| |
| 1.
|
|
|
|
前提 |
| 2.
|
|

|
|
前提 |
| 3.
|
|

|
|
前提 |
|
注意行號和公式之間的豎線。 這是控制子推導的圍欄的一部分。 我們將在下一模組中介紹子推導。 在此之前,我們只在推導的長度上畫一條豎線。 還要注意前提下面的橫線。 這是幫助區分前提與推導中其他行的圍欄。
現在我們需要使用前提。 將 KE 應用於第一個前提兩次,我們將新增以下幾行
| |
| 4.
|
|
|
|
1 KE |
| 5.
|
|
|
|
1 KE |
|
現在我們需要透過應用 CE 使用第二個前提。 由於 CE 有兩個前件行,因此我們首先需要推匯出所需的另一行。 因此,我們將新增以下幾行
| |
| 6.
|
|

|
|
4 DI |
| 7.
|
|
|
|
2, 6 CE |
|
現在我們將透過應用 CE 使用第三個前提。 同樣,我們首先需要推匯出所需的另一行。 新的行是
| |
| 8.
|
|

|
|
5, 7 KI |
| 9.
|
|
|
|
3, 8 CE |
|
第 9 行是 , 這是我們論證的結論,所以我們完成了。 結論並不總是如此順利地出現在我們面前,但這次它確實出現了。 完整的推導如下
| |
| 1.
|
|
|
|
前提 |
| 2.
|
|
|
|
前提 |
| 3.
|
|
|
|
前提 |
| 4.
|
|
|
|
1 KE |
| 5.
|
|
|
|
1 KE |
| 6.
|
|
|
|
4 DI |
| 7.
|
|
|
|
2, 6 CE |
| 8.
|
|
|
|
5, 7 KI |
| 9.
|
|
|
|
3, 8 CE |
|
如前所述,我們還需要三個推理規則:條件引入 (CI)、否定引入 (NI) 和否定消除 (NE)。這些需要子推導。
我們從一個示例推導開始,它說明了條件引入,然後進行解釋。對於以下論證的推導:
 ∴
∴ 
如下所示
| |
| 1.
|
|
|
|
前提 |
|
|
|
|
|
|
| 2.
|
|
|
|
|
假設 |
| 3.
|
|
|
|
|
1 KE |
|
|
|
|
|
|
| 4.
|
|
|
|
2–3 CI |
|
第 2 行和第 3 行構成了一個子推導。它從假設所期望公式的前件開始,並以推匯出所期望公式的後件結束。在行號和公式之間有兩個垂直的柵欄,以將其與推導的其餘部分隔開,並指示其從屬狀態。第 2 行在其下方有一個水平的柵欄,以將假設與子推導的其餘部分隔開。第 4 行是條件引入的應用。它不是從一兩行推斷出來的,而是從整個子推導(第 2-3 行)推斷出來的。
條件引入是一個 *放電規則*。它放電(使無效)該假設,並且實際上使整個子推導無效。一旦我們應用了放電規則,子推導中的任何行(此處為第 2 行和第 3 行)都不能在推導中進一步使用。
為了推匯出一個公式 ,條件引入 (CI) 規則透過首先在子推導中假設前件 為真,然後推匯出 作為子推導的結論來應用。符號上,CI 寫成

此處,後續行不是從一個或多個先行行推斷出來的,而是從整個子推導推斷出來的。註釋是子推導所佔行範圍和縮寫 CI。與之前介紹的推理規則不同,條件引入不能用真值表來證明。相反,它是由 *命題連線詞的性質* 中介紹的演繹原理證明的。為什麼我們假設 為了推匯出 的直覺是,如果 為假,則根據定義 為真。因此,如果我們表明無論何時 碰巧為真, 為真,那麼 一定為真。
請注意,先行子推導可以包含一行,該行同時充當假設的 和推匯出的 ,如下推導所示:
- ∴

| |
| 1.
|
|
|
|
|
假設 |
|
|
|
|
|
|
| 2.
|
|

|
|
1 CI |
|
為了說明否定引入,我們將提供一個針對以下論證的推導:
 ∴
∴
| |
| 1.
|
|

|
|
前提 |
| 2.
|
|
|
|
前提 |
|
|
|
|
|
|
| 3.
|
|
|
|
|
假設 |
| 4.
|
|
|
|
|
2 KE |
| 5.
|
|
|
|
|
3, 4 CE |
| 6.
|
|
|

|
|
2 KE |
|
|
|
|
|
|
| 7.
|
|
|
|
3–6 NI |
| 8.
|
|
|
|
1, 7 CE |
| 9.
|
|
|
|
8 DI |
|
第 3 到第 6 行構成了一個子推導。它從假設所需公式的相反開始,並以假設矛盾(一個公式及其否定)結束。和以前一樣,行號和公式之間有兩個垂直分隔符,將它與推導的其餘部分隔開,並表明其從屬狀態。第 3 行下的水平分隔符再次將假設與子推導的其餘部分隔開。第 7 行,它繼整個子推導之後,是否定引入的應用。
在第 9 行,請注意註釋“5 DI”將是不正確的。儘管從 推斷出 是有效的,當我們到達第 9 行時,第 5 行不再處於活動狀態。因此,我們不允許從第 5 行推匯出任何東西。
否定引入 (NI)

結果行是從整個子推導中推斷出來的。註釋是子推導所佔行的範圍,縮寫是 NI。否定引入有時被稱為拉丁語名稱Reductio ad Absurdum,有時被稱為反證法。
與條件引入一樣,否定引入不能透過真值表來證明。而是透過在命題聯結詞性質中介紹的歸謬原則來證明。
為了說明否定消去,我們將提供一個針對以下論證的推導:
 ∴
∴
| |
| 1.
|
|

|
|
前提 |
|
|
|
|
|
|
| 2.
|
|
|
|
|
假設 |
| 3.
|
|
|
|
|
2 DI |
| 4.
|
|
|
|
|
1 KE |
|
|
|
|
|
|
| 5.
|
|
|
|
2–4 NE |
|
第 2 行到第 4 行構成了一個子推導。與前面的例子一樣,它從假設所需的公式的反面開始,並以假設矛盾(一個公式及其否定)結束。第 5 行緊隨整個子推導而來,是使用否定消除規則的結果。
否定消去 (NE)

結論行由整個子推導推斷得出。註釋是子推導佔用的行範圍,縮寫是 NE。與否定引入一樣,否定消除有時被稱為拉丁語名稱“歸謬法”,有時被稱為“反證法”。
與否定引入一樣,否定消除也由在 句子聯結詞的性質 中介紹的歸謬原理所證明。該規則在引入/消除命名約定中的位置比其他規則稍顯笨拙。與其他消除規則不同,此規則消除的否定並不出現在已推匯出的行中。相反,被消除的否定出現在子推導的假設中。
在本模組中介紹的推理規則,條件引入和否定引入,是放電規則。為了避免使用更復雜的術語,我們可以將 推理規則 中介紹的推理規則稱為“標準規則”。標準規則是一個推理規則,其前件是一組行。放電規則是一個推理規則,其前件是一個子推導。
推導中一行深度是指該行編號與公式之間所站立的籬笆數量。推導中所有行至少具有一個深度。每個臨時假設使深度增加一個。每個放電規則使深度減少一個。
有效行是可以作為標準推理規則的前件行使用的行。特別是,它是一行,其深度小於或等於當前行的深度。無效行是指不是有效行的行。
據說放電規則放電假設。它使其前件子推導中的所有行無效。
子推導可以巢狀。例如,我們提供了一個針對以下論證的推導:
 ∴
∴ 
我們從前提開始,然後假設結論的前件。
注意:每次我們開始一個新的子推導並進入一個臨時假設時,都會有一個特定的公式,我們希望在結束推導和消除假設時推匯出它。為了使事情更容易理解,我們將把這個公式新增到假設的註釋中。該公式不會正式成為註釋的一部分,也不會影響推導的正確性。相反,它將作為我們自己的非正式提醒,說明我們要去哪裡。
| |
| 1.
|
|

|
|
前提 |
| 2.
|
|

|
|
前提 |
| 3.
|
|

|
|
前提 |
|
|
|
|
|
|
| 4.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \lor \mathrm {Q} \rightarrow \lnot \mathrm {R} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aa44596d60b688c05bbdbe0bc7247ed056fb546a) |
|
這開始了一個子推導,以推匯出論證的結論。現在我們將嘗試一個析取消去(DE)以推匯出它的後件

這將需要顯示兩個條件句,我們需要它們作為 DE 的前件行,即

以及

我們從第一個條件句開始。
| |
| 5.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \rightarrow \lnot \mathrm {R} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/94b1bf4e357c16d14c5edd2c38d2d82c0bcf02ac) |
|
|
|
|
|
|
|
|
| 6.
|
|
|
|
|
|
|
假設 ![{\displaystyle [\lnot \mathrm {R} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d8b390160716315f88a8ad089d9a9d61428354ee) |
|
這個子推導很容易完成。
| |
| 7.
|
|
|
|
|

|
|
5, 6 KI |
| 8.
|
|
|
|
|
|
|
1, 7 CE |
| 9.
|
|
|
|
|

|
|
2 KE |
|
現在我們準備消除第 5 行和第 6 行的兩個假設。
| |
| 10.
|
|
|
|
|
|
6–9 NI |
|
|
|
|
|
|
|
| 11.
|
|
|
|
|
5–10 CI |
|
現在是為我們的 DE 計劃(回到第 4 行)所需的第二個條件句。我們開始。
| |
| 12.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {Q} \rightarrow \lnot \mathrm {R} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e985539e01255392f5c1c6fe670de638714a63f8) |
|
|
|
|
|
|
|
|
| 13.
|
|
|
|
|
|
|
假設 |
| 14.
|
|
|
|
|
|
|
2 KE |
| 15.
|
|
|
|
|
|
|
3, 14 CE |
|
注意,在第 12 行和第 15 行之間存在矛盾。但第 12 行在錯誤的位置。我們需要它與第 15 行在同一個子推導中。以下第 16 行和第 17 行的一個愚蠢技巧將實現這一點。然後可以消除第 12 行和第 13 行的假設。
| |
| 16.
|
|
|
|
|

|
|
12, 12 KI |
| 17.
|
|
|
|
|
|
|
16 KE |
|
|
|
|
|
|
|
|
| 18.
|
|
|
|
|
|
13–17 NI |
|
|
|
|
|
|
|
| 19.
|
|
|
|
|
12–18 CI |
|
最後,根據第 4 行、第 11 行和第 19 行,我們可以進行我們從第 4 行開始就一直在期待的 DE 操作。
| |
| 20.
|
|
|
|
|
4, 11, 19 DE |
|
現在,透過撤銷第 4 行的假設來完成推導。
| |
| 21.
|
|
|
|
4–20 CI |
|
以下是完成的推導。
| |
| 1.
|
|
|
|
前提 |
| 2.
|
|
|
|
前提 |
| 3.
|
|
|
|
前提 |
|
|
|
|
|
|
| 4.
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
| 5.
|
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
|
| 6.
|
|
|
|
|
|
|
假設 |
| 7.
|
|
|
|
|
|
|
5, 6 KI |
| 8.
|
|
|
|
|
|
|
1, 7 CE |
| 9.
|
|
|
|
|
|
|
2 KE |
|
|
|
|
|
|
|
|
| 10.
|
|
|
|
|
|
6–9 NI |
|
|
|
|
|
|
|
| 11.
|
|
|
|
|
5–10 CI |
|
|
|
|
|
|
|
| 12.
|
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
|
| 13.
|
|
|
|
|
|
|
假設 |
| 14.
|
|
|
|
|
|
|
2 KE |
| 15.
|
|
|
|
|
|
|
3, 14 CE |
| 16.
|
|
|
|
|
|
|
12, 12 KI |
| 17.
|
|
|
|
|
|
|
16 KE |
|
|
|
|
|
|
|
|
| 18.
|
|
|
|
|
|
13–17 NI |
|
|
|
|
|
|
|
| 19.
|
|
|
|
|
12–18 CI |
| 20.
|
|
|
|
|
4, 11, 19 DE |
|
|
|
|
|
|
| 21.
|
|
|
|
4–20 CI |
|
一個定理是指一個公式,它已經提供了一個零前提推導。我們將保持一個已經證明的定理的編號列表。在接下來的推導中,我們將繼續我們的非正式約定,將公式新增到假設的註釋中,特別是我們希望透過新開始的子推導來推導的公式。
您可能還記得在構造一個複雜推導中,我們不得不使用一個愚蠢的技巧將公式複製到適當的子推導中(第 16 行和第 17 行)。我們可以證明一個定理,它將幫助我們避免這種令人討厭的行為。

| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \rightarrow \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79933dc3c8b22ad47c5f28386ff6e8976b768d5e) |
|
|
|
|
|
|
| 2.
|
|
|
|
1 CI |
|
推導可以透過允許輸入一條公式作為先前證明定理的替換例項來進行縮寫。註釋將是 'Tn',其中 n 是定理的編號。雖然我們不會正式要求,但我們也會在註釋中顯示替換(如果有)(見下面的推導中的第 3 行)。下一個定理的證明將使用T1。

| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {Q} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/94b8be83a1ab88d731a8b904852f116034ad2939) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \rightarrow \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/97cf4af3c1bca8188faa85c99bb829c88690a523) |
| 3.
|
|
|
|

|
|
T1 [P/Q] |
| 4.
|
|
|
|
|
|
1, 3 CE |
|
|
|
|
|
|
|
| 5.
|
|
|
|
|
2–4 CI |
|
|
|
|
|
|
| 6.
|
|
|
|
1–5 CI |
|
我們需要證明在推導中以這種方式使用定理是合理的。為此,我們將展示如何生成T2的正確、非縮寫推導,即不引用我們在其縮寫證明中使用的定理的推導。
觀察到,當我們在 T2 的推導中引入第 3 行時,我們將 代入 T1 中的 。假設您要在 T1 的證明中對每一行應用相同的替換。然後您將得到以下同樣正確的推導。
| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {Q} \rightarrow \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c3c0af0222220bbc7f981fe3c5a3d969cb2fd7a9) |
|
|
|
|
|
|
| 2.
|
|
|
|
1 CI |
|
現在假設您要將 T2 的證明中的第 3 行替換為這個推導。您需要調整行號,以便每行號只有一行。您還需要調整註釋,以便它們引用的行號仍然正確。但是,經過這些調整後,您將得到以下 T2 的正確未縮寫推導。
| |
| 1.
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
|
| 3.
|
|
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
|
3 CI |
| 5.
|
|
|
|
|
|
1, 4 CE |
|
|
|
|
|
|
|
| 6.
|
|
|
|
|
2–5 CI |
|
|
|
|
|
|
| 7.
|
|
|
|
1–6 CI |
|
因此,我們看到,將先前證明的定理引入推導中,僅僅是將該定理的證明包含到推導中的縮寫。上面關於展開推導的說明可以更一般化和更嚴格,但我們將其保留在這個非正式的狀態。有了生成正確展開推導的說明,就可以將先前證明的定理引入推導中。
在接下來的兩個模組中將介紹其他定理。
本頁介紹了推導推理規則的概念,並提供了一些此類規則。
現在我們可以將縮寫進一步推行。推導推理規則是指不是作為推導系統的一部分給我們的推理規則,而是使用先前證明的定理的縮寫。特別是,假設我們已經證明了一個特定的定理。在這個定理中,將每個句子字母統一替換為不同的希臘字母。假設結果具有以下形式。
 .
.
[評論:在我看來,這和接下來的內容可能會讓學生感到困惑。前面幾節中避免元理論的意圖在這裡造成了一些問題,因為需要了解演繹定理才能使它更有意義。]
然後我們可以引入一個具有以下形式的推導推理規則




推導規則的應用可以透過用以下方法替換來消除
- 先前證明的定理,
- 重複使用合取引入(KI)來構建定理的前件,以及
- 使用條件消去(CE)來獲得定理的後件。
然後可以像上面描述的那樣消除先前證明的定理。這將留下一個展開推導。
當然,從推導中刪除縮寫並不理想,因為它會使推導更加複雜,更難閱讀,但推導可以被展開的事實證明了縮寫是合理的,所以我們首先可以使用縮寫。
我們的第一個推導推理規則將基於 T1,它是
將句子字母替換為希臘字母,我們得到

現在我們生成推導的推理規則
- 重複 (R)

現在我們可以展示這個規則如何簡化我們對 **T2** 的證明。
| |
| 1.
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 |
| 3.
|
|
|
|
|
|
1 R |
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
2–3 CI |
|
|
|
|
|
|
| 5.
|
|
|
|
1–4 CI |
|
雖然這僅僅比我們對 **T2** 的原始證明少一行,但它不那麼令人討厭。我們可以使用推理規則而不是愚蠢的技巧。因此,推導更容易閱讀和理解(更不用說更容易產生)。
接下來的兩個定理——以及基於它們的推導規則——利用了雙重否定公式和未否定公式之間的等價性。

| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \rightarrow \lnot \lnot \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5a010f77ae19f9aea6fabf12869899e6216e77bc) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\lnot \lnot \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d56c2499de3ac67a73cdcaca427dce5605b4320b) |
| 3.
|
|
|
|
|
|
1 R |
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
2–3 NI |
|
|
|
|
|
|
| 5.
|
|

|
|
1–4 CI |
|
**T3** 證明了以下規則。
- 雙重否定引入 (DNI)



| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\lnot \lnot \mathrm {P} \rightarrow \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1bb69f44806a433fd72926eb47f9b4ffa7a043c) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81936377579d3940eeb3983f919467358a9f12aa) |
| 3.
|
|
|
|
|
|
1 R |
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
2–3 NE |
|
|
|
|
|
|
| 5.
|
|

|
|
1–4 CI |
|
T4 證明了以下規則。
- 雙重否定消除 (DNE)


| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \land \lnot \mathrm {P} \rightarrow \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/218e914cb2dfec118a310f2d3b6de200ee6e08d2) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b99e6e42dce9a0938a5354e1018054a02fca2ad3) |
| 3.
|
|
|
|
|
|
1 S |
| 4.
|
|
|
|
|
|
1 S |
|
|
|
|
|
|
|
| 5.
|
|
|
|
|
2–4 NE |
|
|
|
|
|
|
| 7.
|
|

|
|
1–5 CI |
|
我們的下一個規則基於 T5。
- 矛盾 (矛盾)

當您推匯出矛盾,但想要使用的推導規則不是 NI 或 NE 時,此規則偶爾會有用。這可以避免完全微不足道的子推導。矛盾規則將用於下一條定理的證明。

| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\lnot \mathrm {P} \rightarrow (\mathrm {P} \rightarrow \mathrm {Q} )]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de406ff15ac87549e0b995a4fa7d7e4dc2b2fea1) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 |
| 3.
|
|
|
|
|
|
1, 2 矛盾 |
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
2–3 CI |
|
|
|
|
|
|
| 5.
|
|

|
|
1–4 CI |
|
基於T2和T6,我們介紹以下推導規則。
- 條件加法,形式 I (CAdd)
- 條件加法,形式 II (CAdd)

“條件加法”這個名稱並不常用。它是基於對析取引入的傳統名稱,即“加法”。這條規則不提供引入條件的通用方法。這是因為您需要的先行項行並不總是可推導的。然而,當先行項行恰好很容易獲得時,應用這條規則比為條件引入產生子推導更簡單。

| |
| 1.
|
|
|

|
|
假設 ![{\displaystyle [(\mathrm {P} \rightarrow \mathrm {Q} )\land \lnot \mathrm {Q} \rightarrow \lnot \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/822876910ec839e4e6294e59bb10a63c5aa3d174) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\lnot \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ebecf005a1793b292d92ddec0a677c0612909c89) |
| 3.
|
|
|
|
|
|
1 KE |
| 4.
|
|
|
|
|
|
2, 3 CE |
| 5.
|
|
|
|
|
|
1 KE |
|
|
|
|
|
|
|
| 6.
|
|
|
|
|
2–5 NI |
|
|
|
|
|
|
| 7.
|
|

|
|
1–6 CI |
|
現在我們用T7來證明以下規則。
- 拒取式 (MT)
拒取式有時也被稱為“否定後件”。請注意,以下不是拒取式的例項,至少根據上面的定義。


拒取式的前提行是一個條件和其後件的否定。該推理的前提行是一個條件和其後件的相反,但不是其後件的否定。這裡需要的推理需要像下面那樣推導。
| |
| 1.
|
|
|
|
前提 |
| 2.
|
|
|
|
前提 |
| 3.
|
|
|
|
2 DNI |
| 4.
|
|
|
|
1, 3 CE |
| 5.
|
|
|
|
4 DNE |
|
當然,可以將它作為一個定理來證明

然後你可以在這個定理的基礎上新增一個新的推理規則——或者更可能的是,一個新的 Modus Tollens 形式。但是,我們在這裡不會這樣做。
到目前為止給出的派生規則對於消除推導中經常使用的一些令人討厭的部分非常有用。它們將有助於使您的推導更容易生成,也更易讀。但是,因為它們確實是派生規則,所以它們不是嚴格要求的,而是理論上可以省略的。
一些其他的定理和派生規則可以有效地新增。我們在這裡列出一些有用的定理,但將它們的證明以及它們相關聯的派生推理規則的定義留給讀者。如果你構造了許多推導,你可能想維護你自己的個人列表,你會發現它很有用。








在目前的推理規則下,推導中的析取很難處理。使用已經推匯出的析取並應用析取消除 (DE) 並不太糟糕,但有一個更易於使用的替代方案。首先推匯出析取更困難。我們的析取引入 (DI) 規則被證明是完成這項任務的相當貧乏的工具。在本模組中,我們引入了派生規則,這些規則提供了處理推導中析取的替代方法。
我們從一個新的(將要)推導的推理規則開始。這將為析取消除 (DE) 提供一個有用的替代方案。
- 拒取式假言推理,形式 I (MTP)

- 拒取式假言推理,形式 II (MTP)

拒取式假言推理有時被稱為析取三段論,偶爾也稱為“狗的規則”。
這個新規則需要以下兩個支援定理。

| |
| 1.
|
|
|

|
|
假設 ![{\displaystyle [(\mathrm {P} \lor \mathrm {Q} )\land \lnot \mathrm {P} \rightarrow \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ce2fd880e79bd95061a9001884c5f98b39d25c94) |
| 2.
|
|
|
|
|
1 KE |
| 3.
|
|
|
|
|
1 KE |
| 4.
|
|
|
|
|
3 CAdd |
| 5.
|
|
|
|
|
T1 [P/Q] |
| 6.
|
|
|
|
|
2, 4, 5 DE |
|
|
|
|
|
|
| 7.
|
|

|
|
1–6 CI |
|

| |
| 1.
|
|
|

|
|
假設 ![{\displaystyle [(\mathrm {P} \lor \mathrm {Q} )\land \lnot \mathrm {Q} \rightarrow \mathrm {P} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/017310eff4f2d7cae3bd6dd40e51e5acc578175e) |
| 2.
|
|
|
|
|
1 KE |
| 3.
|
|
|
|
|
1 KE |
| 4.
|
|
|

|
|
3 CAdd |
| 5.
|
|
|
|
|
T1 |
| 6.
|
|
|
|
|
2, 4, 5 DE |
|
|
|
|
|
|
| 7.
|
|

|
|
1–6 CI |
|
舉個使用 MTP 的例子,我們重新做一下來自 構造複雜推導 的推導示例。
- ∴
| |
| 1.
|
|
|
|
前提 |
| 2.
|
|
|
|
前提 |
| 3.
|
|
|
|
前提 |
|
|
|
|
|
|
| 4.
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
| 5.
|
|
|
|
|
|
假設 |
| 6.
|
|
|
|
|
|
2 KE |
| 7.
|
|
|
|
|
|
3, 6 CE |
| 8.
|
|
|
|
|
|
4, 7 MTP |
| 9.
|
|
|
|
|
|
5, 8 KI |
| 10.
|
|
|
|
|
|
1, 9 CE |
| 11.
|
|
|
|
|
|
2 KE |
|
|
|
|
|
|
|
| 12.
|
|
|
|
|
5–11 NI |
|
|
|
|
|
|
| 13.
|
|
|
|
4–12 CI |
|
在第 4 行之後,我們沒有費心為推匯出 DE 所需的前件行建立子推導。相反,我們直接轉到結論的後件的子推導。在第 8 行,我們應用了 MTP。
下一個推導規則顯著減少了推匯出析取的工作量,從而為析取引入 (DI) 提供了一個有用的替代方案。
- 條件析取 (CDJ)


| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [(\lnot \mathrm {P} \rightarrow \mathrm {Q} )\rightarrow \mathrm {P} \lor \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d274e3f04d76311583944ef8236ff241af80cfab) |
|
|
|
|
|
|
|
| 2.
|
|
|
|
|
|
假設 ![{\displaystyle [\mathrm {P} \lor \mathrm {Q} ]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d908c75773c25f4ce62e273bd9b6b7abe190692f) |
|
|
|
|
|
|
|
|
| 3.
|
|
|
|
|
|
|
假設 |
|
|
|
|
|
|
|
|
|
| 4.
|
|
|
|
|
|
|
3 DI |
| 5.
|
|
|
|
|
|
|
2 R |
|
|
|
|
|
|
|
|
| 6.
|
|
|
|
|
|
3–5 NI |
| 7.
|
|
|
|
|
|
1, 6 CE |
| 8.
|
|
|
|
|
|
7 DI |
|
|
|
|
|
|
|
| 9.
|
|
|
|
|
2–8 NI |
|
|
|
|
|
|
| 10.
|
|

|
|
1–9 CI |
|
這個推導將使用 **T12**(在Derived Inference Rules中介紹),儘管其證明被留給讀者作為練習。以下推導的正確性,特別是第二行,假設您已經證明了 **T12**。
- ∴
| |
| 1.
|
|
|
|
|
假設 ![{\displaystyle [\lnot (\mathrm {P} \rightarrow \mathrm {Q} )\rightarrow (\mathrm {Q} \rightarrow \mathrm {R} )]\,\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4f17aa6df957ee3265b637942af874d9ab1c05c8) |
| 2.
|
|
|

|
|
T12 |
| 3.
|
|
|
|
|
1, 2 CE |
| 4.
|
|
|
|
|
3 KE |
| 5.
|
|
|

|
|
4 CAdd |
|
|
|
|
|
|
| 7.
|
|

|
|
1–6 CI |
| 8.
|
|
|
|
7 CDJ |
|
在這裡,我們試圖透過首先推匯出 CDJ 所需的前項來推匯出所需的條件。
